
我在编写DBSCAN聚类的程序
import matplotlib.pyplot as plt # 导入matplotlib的库
import numpy as np # 导入numpy的包
import pandas as pd
from sklearn.cluster import DBSCAN # 引入DBSCAN模块
from sklearn import metrics # 调用评价指标
data = pd.read_csv('Wine_data.csv', header=None, encoding='GB2312') # 必须要中文解码,设置encoding = ‘GB2312’
wine = data.drop([0], axis=0)
X = np.array(wine)
X = X[:, :11] # 表示我们取特征空间中的11个维度
print(X)
print(X.shape) # 打印出X的尺寸大小
print("===DBSCAN聚类===")
dbscan = DBSCAN(eps=0.4, min_samples=9).fit(X) # 导入DBSCAN模块进行训练
label_pred = dbscan.labels_ # labels为每个数据的簇标签
plt.subplot(2, 2, 3) # 创建单个子图,单个子图中包含4个区域,相应的区域在左下角。
x0 = X[label_pred == 0] # 获取聚类标签等于0的话,则赋值给x0
x1 = X[label_pred == 1] # 获取聚类标签等于1的话,则赋值给x1
x2 = X[label_pred == 2] # 获取聚类标签等于2的话,则赋值给x2
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0') # 画label0的散点图
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1') # 画label1的散点图
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2') # 画label2的散点图
plt.xlabel('DBSCAN') # 设置X轴的标签为DBSCAN
plt.legend(loc=2) # 设置图标在左上角bel_pred)
print(label_pred)
score = metrics.silhouette_score(X, label_pred, metric="euclidean") # 使用轮廓系数
print(score) # 打印出轮廓系数
这是运行结果:
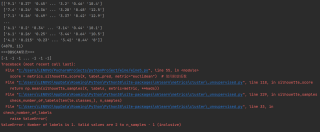
请问是什么原因导致的






