大神,小白请教用正则或者beautifulsoup找到<p中的内容
不知道如何复制源码,这上面显示中文,标签都被省略了,抱歉,xie'xie'da'jia

爬虫爬取<p>和<p,title='...'>中所有<p>的标签?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 threenewbee 2019-07-28 21:38关注
threenewbee 2019-07-28 21:38关注没看到title
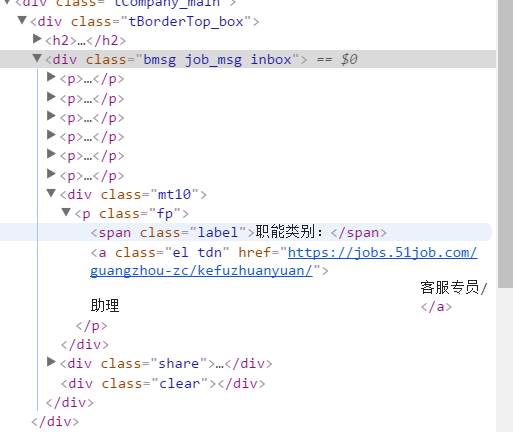
soup.select('p[class="fp"]')[1].text
这个可以得到"客服专员/助理"解决 无用评论 打赏举报 分享
- 2022-07-28 20:30回答 3 已采纳 建议还是使用正则表达式提取会节省内存,主要是由于文件过大,如果使用lxml、bs,会构建完整的数据结构,就会造成内存不足。假设文件是data.html,使用compile对象和re.finditer能
- 2019-04-09 19:08回答 1 已采纳 这里的xml应该是个列表吧,你验证一下,加个循环再用你的方法就可以了
- 2021-05-13 22:48回答 3 已采纳 少了一个空格,没有选中li元素
- 2020-08-17 12:26阿智智的博客 问题描述 爬取新闻网页,HTML代码如下: <div id=ozoom style="ZOOM: 100%"> <founder-content> <P> 上图:1953年3月11日,我国第一座自动化的炼铁炉——...中,我在爬虫代码中匹配时写的仍然是大写
- 2021-04-03 09:45回答 4 已采纳 问题出在urls构造上,第一页和后续网页的地址是不一样的,将这行改为:urls = [f'https://cnblogs.com/#p{page}' if page == 1 else f'https
- 2021-12-26 11:47回答 2 已采纳 先获取所有class='hd'的div保存到列表中,然后遍历列表中每一项获取这一项div的第二个span targets2 = soup.find_all("div", class_="hd") fo
- 2022-05-12 17:23回答 2 已采纳 我估计是link下边没有a,你取了没有的元素再调用string属性就报这个错了,你打印一下link看看吧
- 2021-07-05 17:15weixin_44826979的博客 dict.keys()): if i in str: str = str.replace(i, list(CHAR_ENTITIES_dict.values())[list(CHAR_ENTITIES_dict.keys()).index(i)]) return str # 只保留 标签,去除各种样式,将div、span\标签处理为p标签, def ...
- 2021-11-29 17:50回答 2 已采纳 method默认为xml,设置为html就行了 etree.tostring(h2, encoding="utf-8", method='html')
- 2021-02-21 21:59回答 14 已采纳 楼主请私信我,我可以挨个为你解答每个错误的产生原因以及如何修正。
- 2021-05-30 12:48回答 1 已采纳 问题出在with open(f'红楼梦/{smalltitle}.txt', 'w',encoding='utf-8') as file:这行,文件名中含":",不符合系统对文件名的命名规则,导致无法
- 2019-05-06 20:11weixin_33795833的博客 原博客地址: https://www.cnblogs.com/dengyg200891/p/6060010.html ... 2 #python 2.7 3 #XiaoDeng 4 #http://tieba.baidu.com/p/2460150866 5 #标签操作 6 7 8 from bs4 import ...
- 2022-07-08 23:33回答 3 已采纳 你"iframe[title=’livere‘]"中单引号(')写成了中文全角的,要改成英文半角的。并且你页面中没有title='livere'的iframe只有title='livere-comme
- 2020-11-20 08:28weixin_39667652的博客 从网络上获取网页内容以后,需要从这些网页中取出有用的信息,毕竟爬虫的职责就是获取有用的信息,而不仅仅是为了下来一个网页。获取网页中的信息,首先需要指导网页内容的组成格式是什么,没错网页是由 HTML「我们...
- 2021-06-28 11:12数据分析与统计学之美的博客 所有的Python “爬虫“ 初学者,都应该看这篇文章!
- 2022-09-24 14:52小白fighting.的博客 box-text > p') for content in contents: graph = content.string # 注意br标签 # 由于中间中间会在p标签中遇见一个 标签,而使用content.string时string属性只能匹配成对的标签,所以不进行处理会直接报错。...
- 2021-06-22 19:42秦少爷的琪琪的博客 div class="p-name p-name-type-2"><a target="_blank" title="Apple iPhone 6 (A1589) 16GB 金色 移动4G手机" href="//item.jd.com/1217493.html" onclick="searchlog(1,1217493,0,1,'','flagsClk=419495...
- 2022-03-31 17:37hxgbieshuomeibanfa的博客 python爬虫基础(牛刀小试)
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 c程序不知道为什么得不到结果
- ¥40 复杂的限制性的商函数处理
- ¥15 程序不包含适用于入口点的静态Main方法
- ¥15 素材场景中光线烘焙后灯光失效
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置