import requests
from lxml import etree
import json
# for i in range(1, 4):
# res = requests.get(f'https://www.51shucheng.net/kehuan/santi/santi{i}')
# res.encoding = 'utf-8'
# html = etree.HTML(res.text)
# titles = html.xpath('/html/body/div/div[3]/div[2]/div[6]/ul//li/a/@title')
# hrefs = html.xpath('/html/body/div/div[3]/div[2]/div[6]/ul//li/a/@href')
# for href in hrefs:
# smalltitle = titles[hrefs.index(href)]
# print(smalltitle, href)
# response = requests.get(href)
# response.encoding = 'utf-8'
# html = etree.HTML(response.text)
# text = html.xpath('//*[@id="neirong"]//text()')
# text2 = ''.join(text).replace('(adsbygoogle = window.adsbygoogle || []).push({});','')
# with open(f'三体/{smalltitle}.txt', 'w',encoding='utf-8') as file:
# file.write(text2)
res = requests.get(f'https://www.51shucheng.net/sidamingzhu/hongloumeng')
res.encoding = 'utf-8'
html = etree.HTML(res.text)
titles = html.xpath('/html/body/div/div[3]/div[2]/div[5]/ul//li/a/@title')
hrefs = html.xpath('/html/body/div/div[3]/div[2]/div[5]/ul//li/a/@href')
for href in hrefs:
smalltitle = titles[hrefs.index(href)]
print(smalltitle, href)
response = requests.get(href)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
text = html.xpath('//*[@id="neirong"]//text()')
text2=''.join(text)
with open(f'红楼梦/{smalltitle}.txt', 'w',encoding='utf-8') as file:
file.write(text2)
注释掉的内容爬取的是网站的另一本小说,完全没有问题
下面的是爬取红楼梦
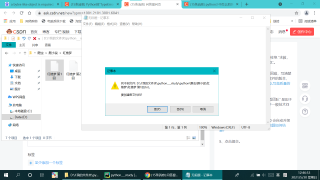
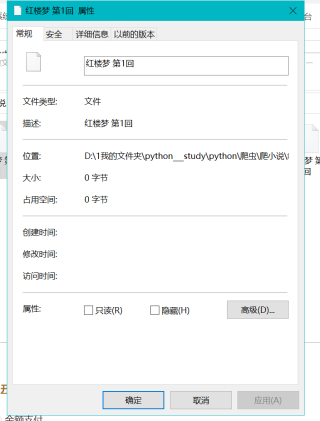
写入文件并没有报错但打开是这个样子