import requests
import re
from lxml import etree
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
url='https://www.zhihu.com/hot'
soup = BeautifulSoup(open('知乎hot页面.html',encoding='utf-8'),'lxml')
file1=open('知乎hot页面.html','w',encoding='utf-8')
file1.write(soup.prettify())
file1.close()
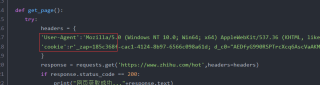
def get_page():
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36',
'cookie':r'_zap=185c368f-cac1-4124-8b97-6566c098a61d; d_c0="AEDfyG990RSPTrcXcq6AscVaAKM-SfvUl2I=|1650436018"; __snaker__id=CZaIBtjh7BGI0fe3; gdxidpyhxdE=RgivM9tbT4lm+2YmEm/u+aKuW3K/4VL6f5SuY3cm\lWCv9vUnvEaUII6R5vhy\O9jpos9gnjl5VRQAHSr39kH6JmbC7mjexMtiyH2nlrgEjrtv15MYi81lTkQiNXhS9XcmxxcbaLcsMHtUpGajBc74WStaZsYLlXea55q2NwxMZZxwo2:1650436918510; _9755xjdesxxd_=32; YD00517437729195:WM_NI=vL6lo0bHJpxw6Kc7NiLoEtVV2GhSSAWATPJcYV1LwZ/H6F48a/5+X11mqaKwbX1K/4fJvc6uDcl99vt77RyKVpCLEEoF8w7uQ2pNI/7KcemTgmOBmWSUt88As1D2xQY5MUk=; YD00517437729195:WM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea6fbb928aa2f568b5868aa7d85f928f8aadc15a958ea6d4c2809cb78ba3d42af0fea7c3b92ab694fa8dee3ca2988691fb7df695add8cd6390b18b95d55ef299a8b4d24b959f9cb1c9699b8affadf652ed98faa7b734a3f1fbccdb3bf3b3bf82ca7da288ffacae40a696ba84b57f88bda4dabc7eb8e9f9b3fc4196b08dadc84fad9af898b67f93eec0afcc25f595ad86f060a5b381a3f05d918bbcd9bb4bb1ef8cd3fb5b9beb83b6ea37e2a3; YD00517437729195:WM_TID=1MGOQ0YHQwZEBQEREAbEBHAyzS5C3RUR; captcha_session_v2=2|1:0|10:1650436036|18:captcha_session_v2|88:RTM0QW1kd3AxSFpLaDROTXQ0Y085THpWVEVPMjBBWVVPcC9BWFJ1aW4yMlNwSEpyN09OaTJva1FGOUw0WUVqNQ==|60cd41f9a0b534d2255fd5a6afab24236d81c7f67b3787fefe81fb2a8cab13ae; captcha_ticket_v2=2|1:0|10:1650436040|17:captcha_ticket_v2|704:eyJ2YWxpZGF0ZSI6IkNOMzFfejQ5VkxtbVhyb2JXMmdqMnA4MHJ0R0ZLYjZseXlZa2s5b09zNkY3SGctOV9hbGF4Q243anVqSUVrWWtTQWlHQ0k4VEF5eUM4Y2lXNmRTbHp1NWZsbm15ZzhxWUZsVWE0Zm1sRlNOdEhKckxiWmptc200cFdDOHBLd3JPWHFkQ0FxLTFXQzB4bXQ2elZ6N3B0bVQ4ZFllRkVFbWRXS2UuUEl2cE5Na1U5RDUuLW5PaXhIdFFheVFMTmZPNXZ1UUR1dXA0eXVjUm9fQk5jcWRObDc1bWdDMHc0a0RVdDhIaWwyenV1NkRMZTZKbURYQTk2LUdZSnJMN1YyRUtNcVAuZEEuZEgxb0JLekdSemNFcU1VRE5mNlVTNUdNblNiOEZNUElpVDE4bjlHYXU1b052bl96UE1jVGRSLS1RNUJNYjE4V2NkZUM2d09Td09jQmU4bC1FT05rRWpoMWxKZnJJRWpQZXFkN0ppazdiei1FNE82QnE4VThoSmdacWouTUVuRXFoalJFT0RIeEN0ZHQwTi5rQzlwd3k1TnRLLkF1bnFZNDZaUy5iYnFoVGJZVG5EZFAtQS04TXVHLVJHYXExbHN0WlpXQU1xRTA3TFE3a2lRbWZhN3VONXJVWUdUWXJtSVBIaTJnMmtadU03VzRybHZFWWdONWZkc0RqMyJ9|f3df51cc5966a9269474d7a364517b61ea55afafe23966206025fa961afa3388; z_c0=2|1:0|10:1650436058|4:z_c0|92:Mi4xQmNSWEN3QUFBQUFBUU5fSWIzM1JGQ1lBQUFCZ0FsVk4ydlZNWXdEU2RtZ3ZmUEFxeDZfcUdtSGZ5eUxDLWd6TkdR|dc1f48c229b16aa32ae19b8826559038b674da54b416ab0d36638dcec768934f; q_c1=986cc29497854513b6ae85c82f874233|1650436058000|1650436058000; tst=h; _xsrf=ca50ce23-6c53-499f-a783-541bbf89e40f; SESSIONID=x7LKH0X9dfWzWJ2ChMfsQme5YWCw9iYnLs9eOV0Tvlb; JOID=U10QBUmU-LkFdm3gG5PPY_cBFzYL6M_2Sj1ZuCHzmu58JSTWWNYoy2BxaeMcJTUeaDBulq-8tPjN1BwrJQqU4QI=; osd=VF0cAEyT-LUAc2rgF5bKZPcNEjMM6MPzTzpZtCT2ne5wICHRWNotzmdxZeYZIjUSbTVplqO5sf_N2BkuIgqY5Ac=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1650436017,1651221589,1651456645,1652075624; NOT_UNREGISTER_WAITING=1; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1652081185; KLBRSID=fe0fceb358d671fa6cc33898c8c48b48|1652081197|1652071589'
}
response = requests.get('https://www.zhihu.com/hot',headers=headers)
if response.status_code == 200:
print("网页获取成功..."+response.text)
return response
else:
print("网页获取失败...")
except RequestException:
return "Request出现异常错误"
def parse_one_page_re(response):
html = response.text
pattern = re.compile('<div class="HotItem-index">.*?>(.*?)</div>.*?'
'<a href="(.*?)".*?'
'<h2 class="HotItem-title">(.*?)</h2>'
'(.*?)</a>.*?'
'<div class="HotItem-metrics.*?</svg>(.*?)<span'
,re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'热搜排名':item[0],
'热搜链接':item[1],
'热搜标题':item[2],
'热搜内容':item[3].replace('<p class="HotItem-excerpt">','').replace('</p>',''),
'热度':item[4],
}
if __name__ == '__main__':
response = get_page()
for item in parse_one_page_re(response):
print(item)
请问这个为什么总是说26行def parse_one_page_re(response):有意外缩进,而且没有输出结果如下图这样的,是哪部分代码有问题吗