关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
qq_37697451
2022-06-15 15:37
采纳率: 100%
浏览 168
首页
人工智能
已结题
训练集效果比验证集效果差
自然语言处理
语言模型
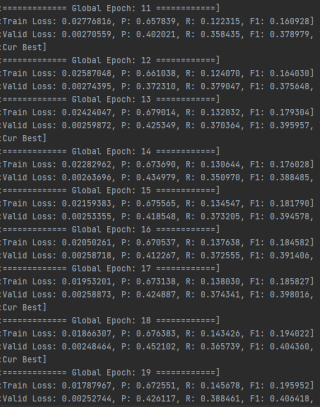
不知道为什么训练集的效果会比验证集的效果差。而且发现训练集的召回率很低。
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
似水不惧
2022-06-17 11:49
关注
这种情况要么就是模型本身参数设置和结构的问题,要么就是数据集少了,一般不会出现训练集比测试集还差
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
机器学习笔记:
训练集
、
验证集
与测试集
2022-03-17 12:51
mooyuan天天的博客
在学习《深度学习原理与pythorch实战》这本书的4.3.4划分数据集这一小节(即76页划分数据集)的过程中,提到了
训练集
、测试集与
验证集
这几个概念,以及为何相对于通用的
训练集
、测试集,多了一个
验证集
的概念。...
【每天一个AI小知识】:什么是
训练集
、
验证集
及测试集?
2025-11-12 19:29
海边夕阳2006的博客
通常将数据分为三个独立部分:
训练集
(70-90%):模型"学习课本",通过大量练习掌握基本能力
验证集
(10-15%):"期中考试",用于调参并防止过拟合 测试集(10-15%):"期末考试",...
人工智能
+python+AI模型训练+LableMe标注+数据集自动划分+项目文档
2024-03-28 10:37
【内容摘要】项目文档:lableMe标注的分割数据划分
训练集
和测试集 【适用人群】AI模型训练(图像分类/分割) 【适用场景】当我们用lableMe标注好了文件后,一般需要对已标注数据集进行有效划分的需求,确保训练过程...
人工智能
训练数据集的构建与使用规范.docx
2025-08-24 13:21
人工智能
训练数据集的构建与使用是当前
人工智能
领域研究的重点之一,其规范的制定对于提高数据集的质量,加速模型训练和验证,以及确保数据安全与隐私保护等方面均具有重要作用。 首先,构建
人工智能
训练数据集的...
AI-基本概念-
训练集
、
验证集
、测试集
2024-10-17 09:44
深度安全实验室的博客
AI-基本概念-
训练集
、
验证集
、测试集
中草药的ai
训练集
2000张
2025-05-18 21:31
中草药AI
训练集
是一种专门为
人工智能
技术应用而准备的数据集合,包含了大量的中草药图像。这份集合共包含2000张图像,这些图像被精心挑选和处理,用于提高计算机视觉系统的识别能力。通过这样的
训练集
,可以帮助AI...
为什么
训练集
效果
不如测试集
2023-02-16 20:35
Mn孟的博客
通常情况下,
训练集
的
效果
应该优于测试集,因为模型是使用
训练集
进行训练的,它应该在
训练集
上表现得比在测试集上好。 但如果
训练集
的
效果
不如测试集,这可能是由于以下几个原因导致的: 过拟合(overfitting):模型...
训练集
、
验证集
、测试集(附:分割方法+交叉验证)
2022-11-13 19:00
地理探险家的博客
数据在
人工智能
技术里是非常重要的!本篇文章将详细给大家介绍3种数据集:
训练集
、
验证集
、测试集。 同时还会介绍如何更合理的讲数据划分为3种数据集。最后给大家介绍一种充分利用有限数据的方式:交叉验证法。
python脚本,划分
训练集
和测试集,coco、voc格式的数据转换成yolo系列数据
2022-06-28 16:10
内容概要:python脚本划分
训练集
测试集。可以把coco、voc格式的数据转换成yolo系列数据。经过大量实践验证无bug 源代码:python脚本 适合人群:学生、具备一定编程基础,工作1-3年的研发人员、想入门
人工智能
的爱好...
人工智能
车牌识别数据集
2022-10-05 10:36
"
人工智能
车牌识别数据集"是为训练和优化AI模型而专门准备的一系列图像和相关数据,这些数据集通常包括
训练集
、测试集和
验证集
,以确保模型在不同阶段的性能评估。
训练集
是用于教授AI模型识别车牌的基础,其中包含...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
7月4日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
6月26日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
6月15日

 分享
分享 分享
分享 系统已结题
7月4日
系统已结题
7月4日 已采纳回答
6月26日
创建了问题
6月15日
已采纳回答
6月26日
创建了问题
6月15日


