数据
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
#通过requests请求到电影票房的页面
text = requests.get(url="http://www.piaofang.biz/")
text.encoding = text.apparent_encoding
#print(text.text)
#通过BeautifulSoup解析:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple beautifulsoup4
main_page = BeautifulSoup(text.text,"html.parser")
#html的解析器
#找到table
table = main_page.find("table")
#
f = open("电影票房.csv",mode="w",encoding='utf-8',newline="")
trs = table.find_all("tr")
#拿到每一个tr
for tr in trs:
lst = tr.find_all("td")#找到每一个td
if len(lst) != 0:
for td in lst:
# print(td.text)
f.write(td.text.strip().replace(',','').strip().replace('$',''))#strip默认去掉左右两边的空白,replace替换数据中的逗号
f.write(',')
f.write("\n")
f.close()
数据分析加画图
import numpy as np
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Pie,Bar,Timeline
###数据提取
data = pd.read_csv("电影票房.csv",encoding = 'utf-8',header=None)
# print(data)
#那到1,2中的数据
data = data.loc[:, [2,3]] #逗号前面的是行,表示都要 后面的表示是列,只要3.5 loc[:, 1:4] 1-4列出现
# print(data)
#拆分类别数据
def func1(item): #/前面的类别
#把类别单独拎出来,数据处理
return item.split('/')[0]#切割类别
def func2(item): #/后面的类别
#把类别单独拎出来,数据处理
if "/" in item:
return item.split("/")[1]#切割类别
else:
return "lxy"
data[6] = data[3].map(func1) #将多出的类别在起一列 后面的是原本的列
data[7] = data[3].map(func2)
# print(data)
#把数据拆分开
data_1 = data.loc[:, [2, 6]]
data_2 = data.loc[:, [2, 7]]
data_2 = data_2.loc[data_2[7] != 'lxy']#将data_2中所有’lxy‘的数据删除
data_2 = data_2.rename(columns={7:6}) #将data_2中的第七列重新命名为6,防止合并出现nan
# print(data_1)
# print(data_2)
# data = data_1.append(data_2)
data = pd.concat([data_1,data_2])#合并
# print(data)
#计算每一种类型的票房的平均值
data = data.groupby([2,6]).size().reset_index()#以第六列为组进行计算,取消year1为默认列
#列数重命名
data.columns = ["year","类型","类型总数"]
# resp = data[data['year']==1982][['类型','类型总数']]\
# .sort_values(by='类型总数',ascending=True).values.tolist() #不包括第一列
#
# print(resp)
#保存处理好的数据
# data.to_csv('年份.csv')
#
###画图
#时间序列
timeline = Timeline()
#播放设置:设置时间间隔 1s 1s=1000ms
timeline.add_schema(play_interval=1000)#毫秒
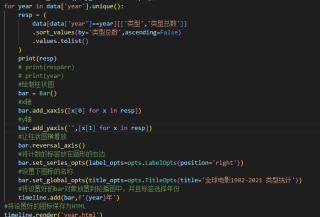
for year in data['year'].unique():
resp = (
data[data['year']==year][['类型','类型总数']]
.sort_values(by='类型总数',ascending=False)
.values.tolist()
)
# print(year)
#绘制柱状图
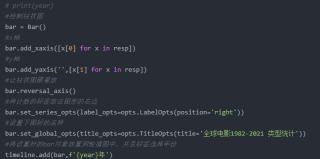
bar = Bar()
#x轴
bar.add_xaxis([x[0] for x in resp])
#y轴
bar.add_yaxis('',[x[1] for x in resp])
#让柱状图横着放
bar.reversal_axis()
#将计数的标签放在图形的右边
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
#设置下图标的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='全球电影1982-2021 类型统计'))
#将设置好的bar对象放置到轮播图中,并且标签选择年份
timeline.add(bar,f'{year}年')
#将设置好的图标保存为HTML
timeline.render('year.html')
为什么只出来2021年的数据,该加什么