
遍历了详情页面,得到了所有的m3u8地址 ,解密了m3u8地址,然后得到了ts,再下载保存 ,用了try去捕获异常 ,没有异常得到每页的视频,运行了没有保存文件,运行出现了问题吗

import requests as rq, re
from lxml import etree
from Crypto.Cipher import AES
show = int(input('请输入show编号:'))
url = f'http://www.yinghuacd.com/show/{show}.html'
h = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'}
r = rq.get(url, headers=h)
rr = r.content.decode('utf-8')
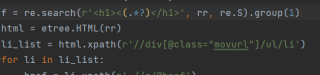
f = re.search(r'<h1><(.*?)</h1>', rr, re.S).group(1)
html = etree.HTML(rr)
li_list = html.xpath(r'//div[@class="movurl"]/ul/li')
for li in li_list:
href = li.xpath(r'.//a/@href')
jishu = li.xpath(r'.//a/text()')
for hrf, ji in zip(href, jishu):
hrf1 = 'http://www.yinghuacd.com' + hrf # 遍历每一个m3u8地址详情页
# print(hrf1)
req = rq.get(url=hrf1, headers=h)
htm = req.content.decode('utf-8')
vid = re.search(r'<div data-vid="(.*?)"', htm, re.S).group(1) # 加密m3u8地址
v = vid.split('$mp4')[0]
v1 = v.split('index.m3u8')[0] + '1500kb/hls/' + 'index.m3u8'
v2 = v.split('index.m3u8')[0] + '1200kb/hls/' + 'index.m3u8'
for u, k in [[v, ''], [v1, ' 1500kb'], [v2, ' 1200kb']]:
filename = f'{f} {ji}{k}.mp4'
print(filename, u)
try:
content = rq.get(url=u, headers=h).text
except:
print(u, "的视频链接出错!")
continue
if "#EXTM3U" not in content:
print("这不是一个m3u8的视频链接!")
continue
cryptor = None
base_url = u.replace(url.split('/')[-1], '')
base_url2 = re.findall(r'https?://[^/]+', u)[0]
if "EXT-X-KEY" not in content:
print("没有加密")
else:
# 使用re正则得到key和视频地址
jiami = re.findall('#EXT-X-KEY:(.*)\n', content)
# print(jiami[0],jiami)
keyurl = re.findall('URI="(.*)"', jiami[0])[0]
# 得到每一个完整视频的链接地址
if keyurl.startswith('/'):
keyurl = base_url2 + keyurl
elif not keyurl.startswith('http'):
keyurl = base_url + keyurl
print(keyurl)
keycontent = rq.get(keyurl, headers=h).content
cryptor = AES.new(keycontent, AES.MODE_CBC, b'0000000000000000')
# 得到每一个ts视频链接
tslist = re.findall('EXTINF:(.*),\n(.*)\n#', content)
print(tslist)
# exit()
newlist = []
for i in tslist:
newlist.append(i[1])
tslisturl = []
for i in newlist:
if i.startswith('/'):
tsurl = base_url2 + i
elif not i.startswith('http'):
tsurl = base_url + i
else:
tsurl = i
tslisturl.append(tsurl)
# 得到解密方法,这里要导入第三方库 pycrypto
# 这里有一个问题,安装pycrypto成功后,导入from Crypto.Cipher import AES报错
# 找到使用python环境的文件夹,在Lib文件夹下有一个 site-packages 文件夹,里面是我们环境安装的包。
# 找到一个crypto文件夹,打开可以看到 Cipher文件夹,此时我们将 crypto文件夹改为 Crypto 即可使用了
# 必须添加b'0000000000000000',防止报错ValueError: IV must be 16 bytes long
# for循环获取视频文件
with open(filename, 'wb') as fg:
for i in tslisturl:
print(i)
res = rq.get(i, headers=h)
# 使用解密方法解密得到的视频文件
if cryptor == None:
cont = res.content
else:
cont = cryptor.decrypt(res.content)
fg.write(cont)









