python爬虫爬取网页内容的时候一直出错,然后仔细看了一下爬取的网页源代码,发现都是一堆无规则大小写英文字母,跟网页看到的源代码根本不一样,这些英文字母就跟乱码一样。为什么会出现这种情况啊?好多次都是因为这个原因爬取不到,有什么解决办法吗
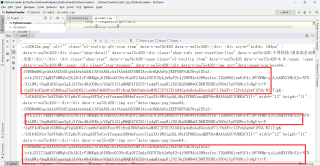

python爬虫爬取网页内容的时候一直出错,然后仔细看了一下爬取的网页源代码,发现都是一堆无规则大小写英文字母,跟网页看到的源代码根本不一样,这些英文字母就跟乱码一样。为什么会出现这种情况啊?好多次都是因为这个原因爬取不到,有什么解决办法吗
 分享
分享
这不是乱码,其实这一串字符串是,img标签中的图片使用base64编码的结果
分享 系统已结题
7月29日
系统已结题
7月29日 已采纳回答
7月21日
创建了问题
7月17日
已采纳回答
7月21日
创建了问题
7月17日



