请问YOLOV5 检测视频时如何将每一帧的图像都保存下来,需要在当帧检测完成后完成画框就保存,而不是结束后对视频进行切分。
目前使用过cv2.imwrite,但是只能保存有目标的帧。修改部分代码如下:
vidcut_dir = str(save_dir) + '/vidcut'
if not os.path.exists(vidcut_dir):
os.makedirs(vidcut_dir)
vidcut_path = vidcut_dir + '\\' + str(p.stem) + ('' if dataset.mode == 'image' else f'_{frame}')
# Write results
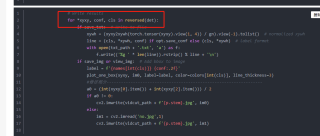
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
#修改部分-----------------------------------------------------------------
a0 = (int(xyxy[0].item()) + int(xyxy[2].item())) / 2
if a0 != 0:
cv2.imwrite(vidcut_path + f'{p.stem}.jpg', im0)
else:
im1 = cv2.imread('no.jpg',1)
cv2.imwrite(vidcut_path + f'{p.stem}.jpg', im1)