爬虫入门,为什么我爬到的数据和网页的不一样。
我是先爬取整个页面,再从中截取ul部分,最后在ul的li里获取想要的文字内容
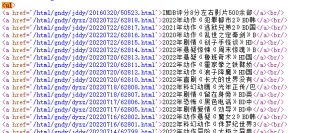
这是dytt的网页源码,这个是ul部分:
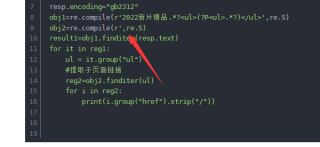
我的代码如下(用了预加载compile),但想要查看爬取的子页面链接时,却发现和源码显示的不一样:
import requests
import re
domain="https://www.dydytt.net/index2.htm"
#发送请求并解除安全认证
resp=requests.get(domain,verify=False)
#指定字符集(编码)
resp.encoding="gb2312"
obj1=re.compile(r'2022新片精品.*?(?P.*?)
'
,re.S)
obj2=re.compile(r'<a href="(?P<href>.*?)"',re.S)
result1=obj1.finditer(resp.text)
for it in reg1:
ul = it.group("ul")
#提取子页面链接
reg2=obj2.finditer(ul)
for i in reg2:
print(i.group("href").strip("/"))