
使用python的requests库爬取百度搜索页面的时候,同样的代码,UA是从浏览器复制的,cookie也按照浏览器的复制添加到请求头了,为什么家里的电脑可以正常获取网页数据而另一台电脑获取的全是乱码?有人可以解答一下吗,谢谢啦。PS:这里的乱码不是中文乱码。而是数据全部乱码,具体可以见下面截图。
这里是用到的代码部分
import requests
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,/;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Connection": "keep-alive",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.baidu.com",
"Cookie": "这里一长串就不复制了太占地方,就是直接从浏览器扒出来的cookie"
}
page = 0
v_text = "查询内容"
url = 'http://www.baidu.com/s?wd=%27 + v_text + '&pn=' + str(page * 10)
r = requests.get(url,headers=myheaders)
以上是获取页面信息部分
正常和异常数据对比图如下
首先是在家里电脑的正常数据截图:

以及输出的信息截图:
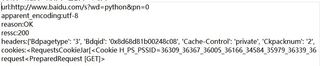
可见状态码200,数据正常
但使用另一台电脑运行同样代码后数据为:

输出信息为:

可见无法异常时获得的数据全部为乱码并且requests库无法检测出数据编码格式。
我又将为解码的数据(即r.content)输出,发现同样为乱码,如下图:

并且异常时的数据长度比正常时的数据长度小得多。正常大概800多KB而异常的只有100多KB







