

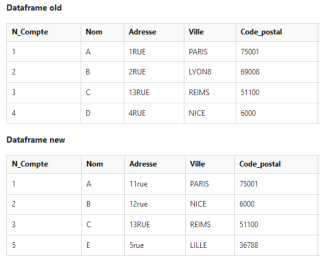
我需要对比两个相似性很大的表格
结构性区别和内容性区别
新表格可能会莫名其妙多一行,可能会少一行,内容可能发生异常。
我借用网站其他人的解决思路(暂时没有link,如果谁看到了的dm我,我将会把来源附上)
本人没有cs背景,都是自己摸索找资源的。
先提前感谢大家了/(ㄒoㄒ)/~~
目前结构性区别有output已经ok并成功写入新文件新的sheet
问题主要出现在把结构性差异排除后,对剩余的数据对比,看是否有内容性的差异
相关代码如下:
import numpy as np
import pandas as pd
old=pd.read_excel(io=r'sample_old.xlsx',sheet_name='sheet1', na_values=['NA'])
new=pd.read_excel(io=r'Csample_nouveau.xlsx', sheet_name='sheet1', na_values=['NA'])
old['version'] = "old"
new['version'] = "new"
old_comptetotal=set(old['N_Compte'])
new_comptetotal=set(new['N_Compte'])
suppr_compte=old_comptetotal-new_comptetotal
ajoute_compte=new_comptetotal-old_comptetotal
print(suppr_compte)
print(ajoute_compte)
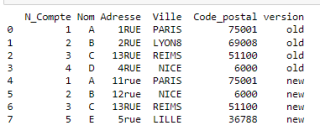
all_data=pd.concat([old,new],ignore_index=True)
changes=all_data.drop_duplicates(subset=old.columns,keep='last')
print(changes)
cpt_double=changes[changes['N_Compte'].duplicated()==True]['N_Compte'].tolist()
print(cpt_double)
double=changes[changes['N_Compte'].isin(cpt_double)]
print(double)
change_new=double[(double["version"]=="new")]
change_old=double[(double["version"]=="old")]
print(change_new)
print(change_old)
change_new=change_new.drop(["version"],axis=1)
change_old=change_old.drop(["version"],axis=1)
print(change_new)
print(change_old)
df_all_changes=pd.concat([change_new,change_old],axis='columns',keys=['old','new'],join='outer')
df_all_changes=df_all_changes.swaplevel(axis='columns')[change_new.columns[0:]]
print(df_all_changes)
后面没有代码了,因为我解决不了了
问题
最后print出来发现old和new没有区别的行也被print了,我想去除没有差异的那一行。
如图我highlight部分,每一列名称下的old new都是没有差异的
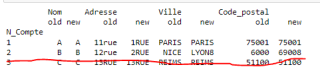
但是我不可能单独drop那一行,这是个样本表格,真实表格很多数据,有差异的概率比较小,因此写入新excel应该是有差异的那几行以便于更改。
**我的解答思路和尝试过的方法 **
我尝试highlight diff,然后条件筛出有颜色的那一行,但是本人python知识浅薄,highlight出了difference但是那一行还在/(ㄒoㄒ)/~~。
我想要达到的结果
有没有highlight不重要,我只要内容有差异的行,且格式是每个列名下有old 和new对比。这样一眼看的出差异

如图是我想要被写入的样子








