没有报错,最后一个函数写错了,是不是编译器原因没报错,有问题的我帮你改好了,看看注释
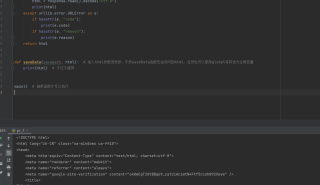
import urllib.request, urllib.error
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath = ".\\豆瓣电影TOP250.xls"
html = askURL("https://movie.douban.com/top250?start=") # 获取返回参数
saveData(savepath, html)
def getData(baseurl):
datalist = []
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askURL(url)
return datalist
def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
def saveData(savepath, html): # 加入html参数进传参,不然saveData函数无法访问到html,当然也可以使用global将其设为全局变量
print(html) # 不过不推荐
main() # 调用函数才可以执行











