

最近在学习python数据分析,刚接触pycharm不久,在学习参考有关书籍的代码时,遇到一些问题不太明白,希望有人能给予解答,十分感谢!
问题如下:
在导入sklearn包自带数据集和导入自己的数据集时,打印输出的结果格式不一样,不知道是什么原因?
1、导入sklearn包自带数据集及输出结果如下:
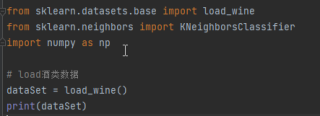
输出结果:
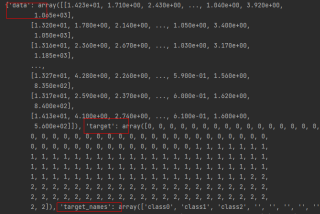
查看sklearn包数据集原始数据,发现就是普通的CSV格式,且里面并没有“data”、“target”、“target_name”等关键字
sklearn包数据源:
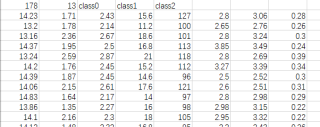
2、导入自己的数据集及输出结果如下:
通过pandas方式导入数据集:
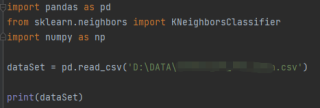
输出结果:
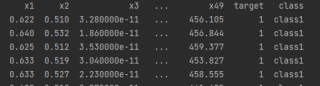
不知道为何上述两种方式的输出结果不一样,看数据导入源码并没有做任何变换,
Q1:为何sklearn包的数据集的输出格式已经分类,而自己的数据集就是普通格式,背后的原理是什么?
Q2:自己的数据集能否实现与sklearn包的数据集相同的输出效果?
希望有人能给予解答,十分感谢!








