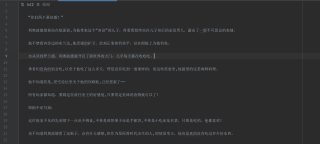
我爬的小说-正文又不换行了,哭唧唧o(╥﹏╥)o 求帮帮忙
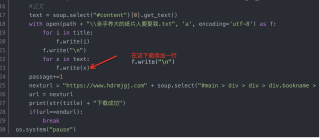
import requests
from bs4 import BeautifulSoup
import os
path = os.getcwd()
passage = 0
url = "https://www.hdrmjgj.com/37/37804/78081218.html"
endurl ="https://www.hdrmjgj.com/37/37804/78688343.html"
head = {}
head['user-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
while True:
r = requests.get(url, headers=head)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
#标题
title = soup.select("#main > div > div > div.bookname > h1")[0].get_text()
#正文
text = soup.select("#content")[0].get_text()
with open(path + "\\亲手养大的纸片人要娶我.txt", 'a', encoding='utf-8') as f:
for i in title:
f.write(i)
f.write("\n")
for x in text:
f.write(x)
passage+=1
nexturl = "https://www.hdrmjgj.com" + soup.select("#main > div > div > div.bookname > div.bottem1 > a.next")[0]['href']
url = nexturl
print(str(title) + "下载成功")
if(url==endurl):
break
os.system("pause")
我现在爬出来是这样的
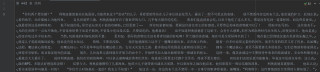
我想要他爬出来是这样的