您好,关于您提出的使用python提出pdf中的指定数据信息,已经为您写好了程序。
最后的效果:
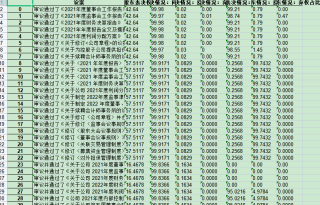
核心代码:
partern_total = r'[0-9]+\.[0-9]*|-?[0-9]+%'
result_total = re.findall(partern_total,text_total_find)
total = 0
if result_total:
total = result_total[0]
partern_detail = r'[、\s{0,2}|(.*?)]*[逐项]*(审议[并]{0,1}通过[了]{0,1}.*?)\n'
result_detail = re.findall(partern_detail, text_detail_find)
if result_detail:
for i in range(len(result_detail)):
dict_data = {}
text_detail_find = text_detail_find[text_detail_find.find(result_detail[i]):]
#修正标题
if "《" in result_detail[i] and '》' not in result_detail[i]:
result_detail[i] = text_detail_find[0:text_detail_find.find('》')+1]
result_detail[i] = re.sub('\n','',result_detail[i])
title = result_detail[i]#议案标题
dict_data['议案'] = title
dict_data['出席股东表决权占比'] = total
if i!=(len(result_detail)-1):
current_text = text_detail_find[0:text_detail_find.find(result_detail[i+1])]
else:
current_text = text_detail_find
result_data = re.findall('(同意|反\n?对|弃\n?权).*?([0-9]+\.[0-9]*|-?[0-9]+)[%|%]',current_text,re.S)
if (len(result_data)!=3 and len(result_data)!=6) or not re.findall('反\n?对',current_text):
continue
dict_data['总体表决情况:同意占比'] = result_data[0][1]
dict_data['总体表决情况:反对占比'] = result_data[1][1]
dict_data['总体表决情况:弃权占比'] = result_data[2][1]
if len(result_data)==6:
dict_data['中小股东表决情况:同意占比'] = result_data[3][1]
dict_data['中小股东情况:反对占比'] = result_data[4][1]
dict_data['中小股东情况:弃权占比'] = result_data[5][1]
else:
dict_data['中小股东表决情况:同意占比'] = '0.00'
dict_data['中小股东情况:反对占比'] = '0.00'
dict_data['中小股东情况:弃权占比'] = '0.00'
# print(dict_data)
pddata = pd.DataFrame(dict_data,index=[0])
all_data = pd.concat([all_data,pddata],ignore_index=True)












