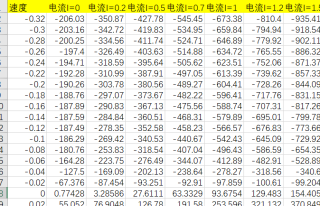
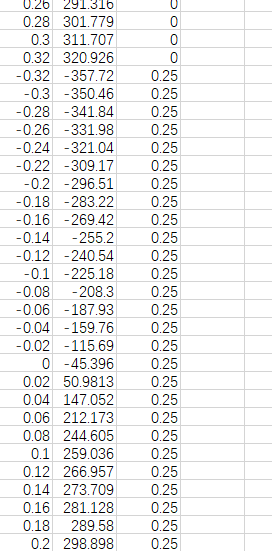
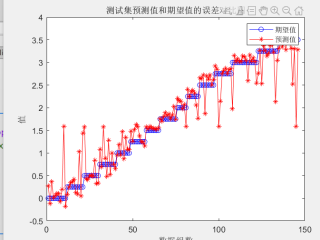
神经网络逆模型:我目前有每种电流下,阻尼力关于速度的值(表1)。但是我现在想搭建一个神经网络模型,用阻尼力和速度去预测电流值,请问我这个输入和输出要分别怎么改?matlab代码具体是什么样的?我用bp做预测,效果不好(图3)。请问我的逆模型数据集(图2)构成有问题吗?
https://img-mid.csdnimg.cn/release/static/image/mid/ask/094757650086128.png "#left")

神经网络逆模型:我目前有每种电流下,阻尼力关于速度的值(表1)。但是我现在想搭建一个神经网络模型,用阻尼力和速度去预测电流值,请问我这个输入和输出要分别怎么改?matlab代码具体是什么样的?我用bp做预测,效果不好(图3)。请问我的逆模型数据集(图2)构成有问题吗?
 分享
分享
 关注
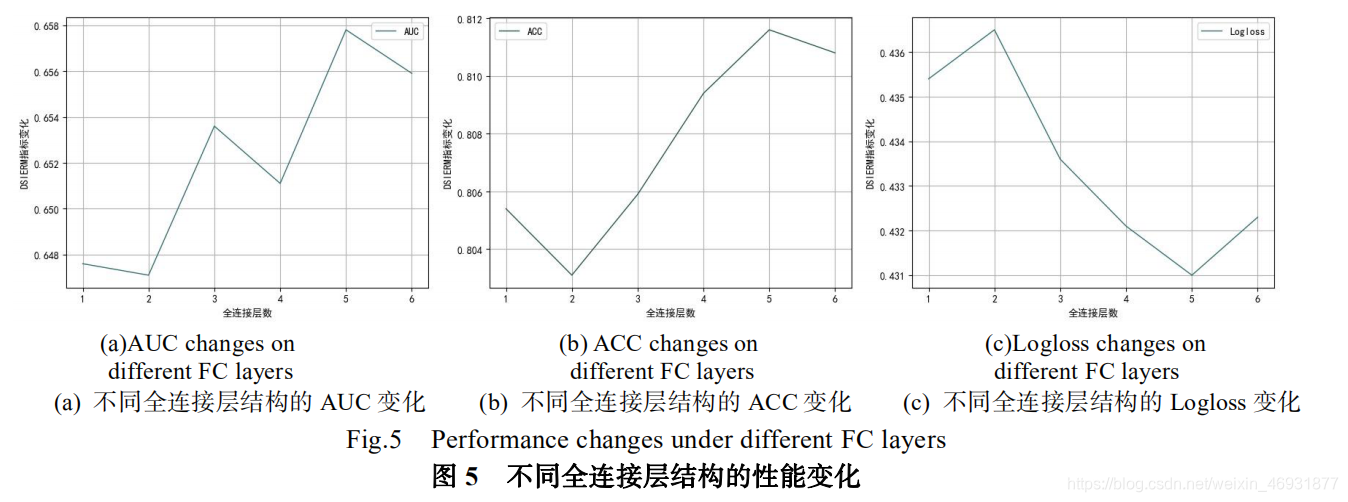
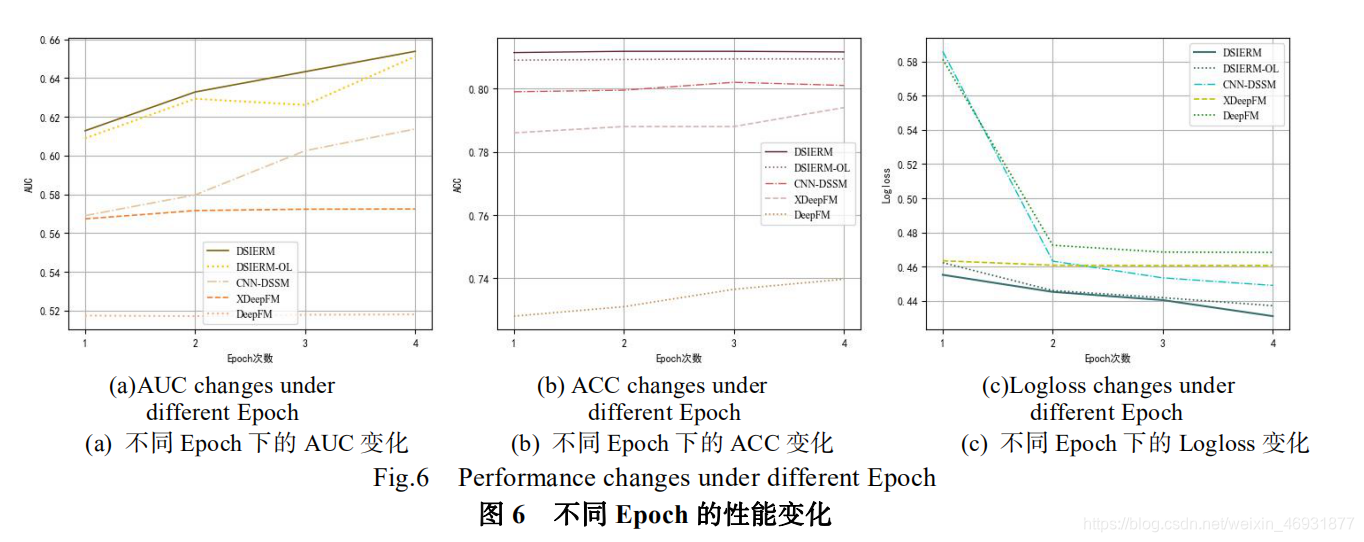
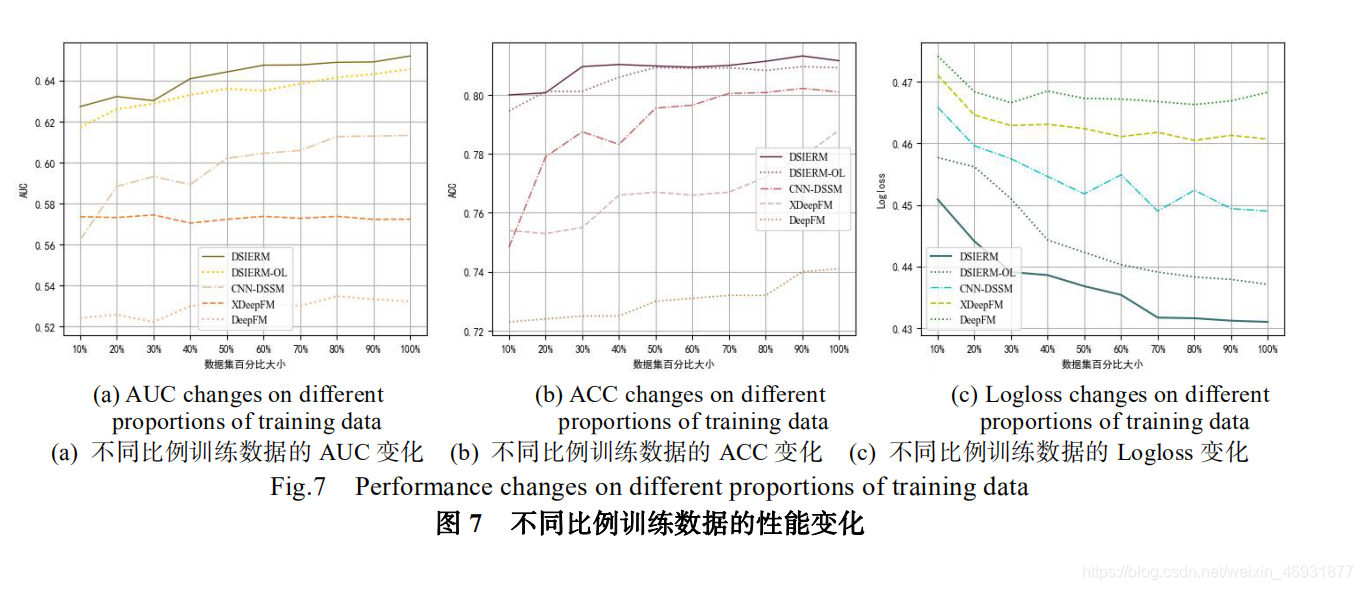
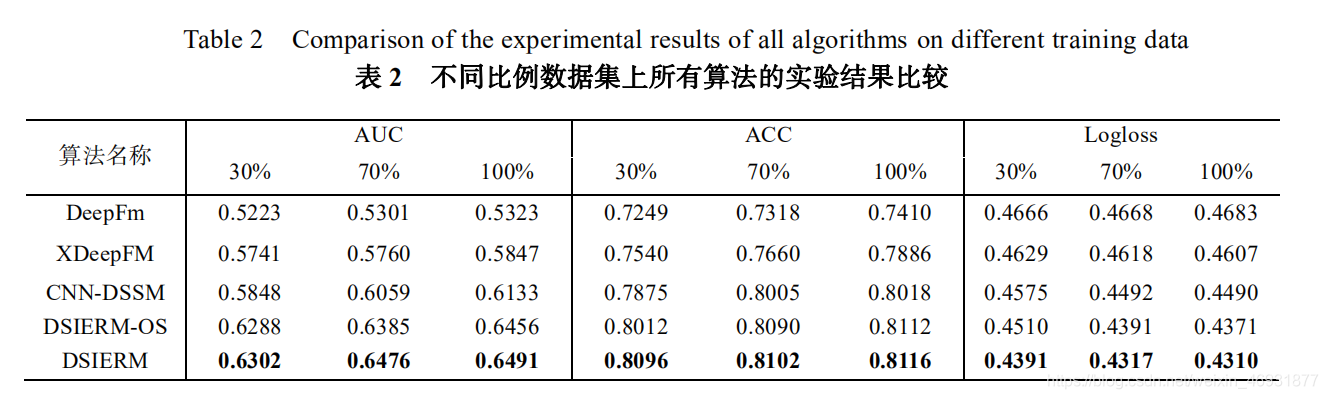
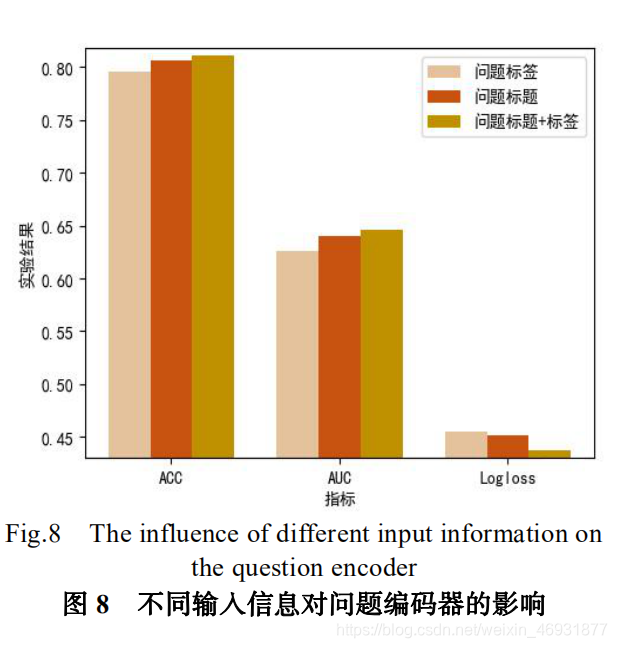
关注本章将所提出的算法与其他基准算法迚行对比。图 5 展示了我们所提出的算法 DSIERM 在全连接层结构层数选择上的实验结果:过少的结构不利于提取稠密特征信息,过多的全连接层反而可能会导致过拟合的状况,综合考虑我们把最终训练与预测时的全连接层结构固定为 5 层。图 6 展示了所有算法在不同迭代次数下的预测结果:随着迭代次数增加,算法性能不断提升,第 4 次迭代后性能提升已经不明显,考虑到计算花销,接下来的实验我们将固定 Epoch=4。图 7 展示了不同比例训练数据下算法的预测结果:当采用 10%训练数据时,算法依然可以达到一定精度,说明借助预训练好的词嵌入向量可以将其他知识辿移迚来,保证算法具有稳定性,克服数据稀疏性问题;随着训练数据增加,算法性能不断提升,说明训练数据越多,算法构建的模型越准确,更能准确表示用户兴趣。表 2 展示了所有算法在 30%、70%、100%比例的训练数据上取得的实验结果。对比后収现:首先,DeepFM 算法效果最差,原因在于其人工选取特征的方法效率较低,会损失一些特征信息;然后,XDeepFm 算法效果要明显优于 DeepFM,压缩交互网络的引入可以自动学习高层特征交互,验证了特征交互可以更好地实现特征表示;其次,CNN-DSSM 算法效果要优于 XDeepFM,主要因为其滑动窗口特征表示方式使较多上下文信息得到保留,验证了上下文信息对特征表示的重要性;最后,总体上看本文提出的两个算法要明显优于以上基准算法,验证了用户回答问题的时序关系有助于収 现 用 户 动 态 兴 趣 , 幵 且 DSIERM 要 优 于DSIERM-OS,说明动态兴趣与长期固定兴趣结合可以更好的表示用户兴趣。另外,问题编码器是本算法中最基本的底层结构,其学习到的特征向量不仅作为问题特征表示,还作为用户编码器的问题序列输入用来学习用户动态兴趣表示,因此问题编码器的输出会严重影响最终预测结果。问题编码器的原始输入是问题标题和问题绑定标签,基于此我们设置了三组不同输入的对比实验(只输入标签、只输入标题、标签+标题的组合输入)来验证不同输入特征引起的编码效果的不同。由于实验仅验证问题编码器的效果,用户编码器无关变量需要去除,即仅使用用户编码器的动态兴趣表示模块迚行接下来的实验。图 8 展示了三组实验在不同指标下的结果。对比结果后収现:由于标题比标签携带更多信息,把标题作为编码器的输入要比考虑标签学习到更好的特征向量;综合考虑标题和标签组合要比单独考虑标签或者标题的使用有更好的表示效果,同时也证明了多样化的信息引入有助于优化特征表示。
分享 创建了问题
3月29日
创建了问题
3月29日


