

请问为什么这个代码只能爬取每一页的第一条评论啊?是循环有什么问题吗?求解。
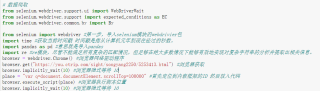
def drag_code(self):
time.sleep(0.5) #在执行查询之前,加一个延时time.sleep(0.5) #在执行查询之前,加一个延时
image_info = self.track.get_image()
all_comments = [] #所有评论
xingji = []
shijian = []
zp_time = []
tp_ner = []
zhichi = []
huifu = []
for i in range(13):
for j in range(1,11):
all_comments.append(browser.find_element(By.XPATH, "//div[@class = 'commentList']/div[@class = 'commentItem']/div[@class = 'contentInfo']/div[@class='commentDetail']".format(j)).text)
xingji.append(browser.find_element(By.XPATH, "//div[@class = 'commentList']/div[@class = 'commentItem']/div[@class = 'contentInfo']/div[@class = 'scroreInfo']/span[@class = 'averageScore']".format(j)).text)
shijian.append(browser.find_element(By.XPATH, "//div[@class = 'commentList']/div[@class = 'commentItem']/div[@class = 'contentInfo']/div[@class = 'commentFooter']/div[@class='commentTime']".format(j)).text)
bot = browser.find_element(By.XPATH, "//div[@class = 'poiDetailPage']/div[@class = 'moduleWrap']/div[@class = 'mainModule']/div[@class = 'commentModuleRef']/div[@class = 'commentModule normalModule']/div[@class = 'myPagination']/ul[@class = 'ant-pagination']/li[@class = ' ant-pagination-next']/span[@class = 'ant-pagination-item-comment']")
browser.execute_script("arguments[0].click();",bot)#通过XPath定位败#浏览器执行脚本
time.sleep(2)#使当前正在执行的Python程序进入睡眠或延迟几秒钟。
browser.implicitly_wait(3)#浏览器隐式等待 3
print(i)







