
用python编写爬虫程序,将文字和图像等信息抓取到sqlite中保存,须有整理

关于#python#的问题:用python编写爬虫程序,将文字和图像等信息抓取到sqlite中保存

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

 关注
关注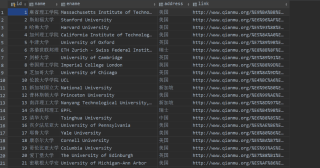
import sqlite3 import re import requests from lxml import html findlink = re.compile(r'<a href="(.*?)"') # 创建正则表达式对象,表示规则(字符串的模式) findname = re.compile(r'<a href=".*?">(.*?)</a>') findname2 = re.compile(r'<td style="outline: 0px !important;">(.*?)</td>') findname3 = re.compile( r'<td style="outline: 0px !important;"><p style="line-height: 1.8; outline: 0px !important;">(.*?)</p></td>') findname4 = re.compile( r'<td style="outline: 0px !important;"><p style="line-height: 1.8; outline: 0px !important;"><a href=".*?">(.*?)</a>.*?</p></td>') findaddres = re.compile(r'<td style="outline: 0px !important;">(.*?)</td>') findadress1 = re.compile(r'<td style="outline: 0px !important;"><a href=".*?">(.*?)</a></td>') ''' 通过findall找到所有table里面的tr 然后对tr里面的内容进行解析,如果没有链接,则data添加信息为空,有链接调用函数来解析链接网页 再向数据库传输解析内容 ''' def main(): basicurl = "http://www.qianmu.org/ranking/1528.htm" datalist = getData(basicurl) for data in datalist: print(data) saveDatadb(datalist,"university.db") # 得到一个指定的网页内容 def askURL(url): et = html.etree respon = requests.get("http://www.qianmu.org/ranking/1528.htm") selector = et.HTML(respon.text) return selector # 爬取主网页,将网页的tr提取出来进行分析 def getData(basicurl): datalist = [] selector = askURL(basicurl) # 找出每个tr,对每个tr解析 trs = selector.xpath('//div[@class="rankItem"]//tr[position()>1]') # names = selector.xpath('//div[@class="rankItem"]//tr[position()>1]/td/a/text() | //div[@class="rankItem"]//tr[' # 'position()>1]/td[2]/text()') # links = selector.xpath('//div[@class="rankItem"]//tr[position()>1]/td/a/@href') # 获得了每一个tr内容 for tr in trs: data = [] tr = html.tostring(tr, encoding='utf-8').decode('utf-8') name = re.findall(findname, tr) name1 = re.findall(findname2, tr) if len(name) == 0: name = name1[1] else: name = name[0] data.append(name) # 获取英文名字 if len(re.findall(findname4, tr)) > 1 or len(re.findall(findname4, tr)) == 1: english = ''.join(re.findall(findname4, tr)[0]) else: english = re.findall(findname3, tr)[1] data.append(english) if len(re.findall(findadress1, tr)) > 1: address = ''.join(re.findall(findadress1, tr)[1]) else: address = re.findall(findaddres, tr)[3] data.append(address) link = re.findall(findlink, tr) # if len(link) > 1: # link = link[0] # elif len(link) == 0: # link = ' ' # else: # link = ''.join(link) # 开始对link进行分析 if len(link) > 1: link = link[0] elif len(link) == 0: link = ' ' else: link = ''.join(link) data.append(link) datalist.append(data) return datalist # 保存数据 def saveDatadb(datalist, dbpath): init_db(dbpath) conn = sqlite3.connect(dbpath) cur = conn.cursor() # 获取游标 # print("我执行了") for data in datalist: for index in range(len(data)): data[index] = '"' + str(data[index]) + '"' # '"'+data[index]+'"' sql = ''' insert into university( name, ename, address, link) values (%s)''' % ",".join(data) # print(sql) cur.execute(sql) conn.commit() # 提交 cur.close() conn.close() # 关闭链接 # 创建数据库 def init_db(dbpath): sql = ''' create table university( id integer primary key autoincrement, name text , ename text , address text , link text ); ''' conn = sqlite3.connect(dbpath) # 建表 cursor = conn.cursor() # 游标 cursor.execute(sql) # 执行sql语句建表 conn.commit() # 提交 conn.close() # 关闭 if __name__ == "__main__": # 当程序执行时,调用函数 这样写的目的是严格控制函数执行的主流程 main()本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-06-26 21:24soengyuchannn的博客 import sqlite3 def opendb(): con = sqlite3.connect("D:/realtimehot.db") cur = con.execute("""create table if not exists realtimehot(snum text primary key, swords text, slink text)""") return cur,
- 2024-09-03 15:20Python爬虫是一种使用Python编程语言编写的自动化脚本,用于从网站上抓取数据。爬虫可以用于多种用途,如数据收集、市场研究、网站监控等。以下是Python爬虫的基础知识、爬虫实例项目资源的详细讲解。 Python爬虫...
- 2025-08-03 14:01使用Python编写租房信息爬虫源码,以自如为例的知识点涵盖了Python编程、网络爬虫的构建、数据采集和分析等多个方面。首先,Python作为一种广泛使用的高级编程语言,以其简洁易读、高效率等特点,在数据分析、网络...
- 2023-09-03 23:14Python爬虫程序,特点:使用Python编写脚本,提供强大的APIPython,强大的WebUI和脚本编辑器、任务监控和项目管理和结果查看支持JavaScript页面后端系统支持:MySQL, MongoDB, SQLite, Postgresql支持任务优先级、重...
- 2025-07-22 07:53Python爬虫技术已经成为网络信息采集的重要工具之一,尤其在数据挖掘、市场调研和内容聚合等领域应用广泛。本案例中,一个专注于电影资源的信息爬虫被编写出来,它的目标是互联网电影数据库IMDb,目的是抓取那些广受...
- 2024-10-03 13:52Python作为一种广泛使用的高级编程语言,因其简洁的语法和强大的功能库,在编写网络爬虫方面表现出色。Scrapy是Python中最著名的爬虫框架之一,它是一个快速、高层次的屏幕抓取和网页抓取框架,用于抓取网站并从页面...
- 2024-01-03 19:56Python 编写的爬虫程序是信息技术领域中一种用于自动化数据抓取的技术,它允许开发者从互联网上批量获取信息。Python 作为一门高级编程语言,因其语法简洁、库丰富而成为编写爬虫的理想选择。本篇将深入探讨Python...
- 2025-07-17 13:23内容概要:本文详细介绍如何使用Python爬虫从[平台名称]抓取数据,涵盖从环境搭建到数据存储的全流程。首先介绍了爬虫的重要性及其应用场景,随后详细讲解了Python爬虫的搭建环境,包括安装Python及相关库(requests...
- Scrapy-Amazon-Sqlite项目是一个使用Python编程语言和Scrapy框架从亚马逊网站抓取背包产品的信息和相关图片,然后将这些数据存储到SQLite数据库中的示例应用。这个项目为那些想要学习网络爬虫和数据存储的初学者提供...
- 2022-03-18 21:59Python网络爬虫是一种用于自动化获取网页数据的技术,它在信息技术领域有着广泛的应用,尤其是在数据分析、信息挖掘和搜索引擎...在实践中,不断提升对网络数据的抓取和处理能力,将网络上的信息转化为有价值的资源。
- 没有解决我的问题, 去提问


问题事件
 系统已结题
6月13日
系统已结题
6月13日 已采纳回答
6月5日
已采纳回答
6月5日-
创建了问题
6月4日