关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
cros1
2023-04-07 18:07
采纳率: 0%
浏览 22
首页
人工智能
已结题
LASSO回归的解为什么要在平方误差项与正则化项之间折中
机器学习
数据挖掘
回归
如图,LASSO回归的解为什么要在平方误差项与正则化项之间折中,如何理解?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
CSDN-Ada助手
CSDN-AI 官方账号
2023-04-07 20:22
关注
这个问题的回答你可以参考下:
https://ask.csdn.net/questions/7497412
我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:
应用预测建模第六章线性回归习题6.1【主成分分析,模型的最优参数选择与模型对比 ,多元线性回归,稳健回归,偏最小二乘回归,岭回归,lasso回归,弹性网】
除此之外, 这篇博客:
机器学习复习
中的
7、LASSO和岭回归的损失函数
部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
AI监督学习算法:线性
回归
(最小二乘法、
正则化
(Ridge/
La
sso
))深度
解
析
2025-06-17 09:42
Clf丶忆笙的博客
在理论部分,详细阐述了线性
回归
模型的定义、最小二乘法原理及其几何
解
释,并分析了参数估计的统计性质。实现部分探讨了数值计算方法(Cholesky分
解
、QR分
解
、SVD)及其复杂度比较,针对不同数据规模推荐相应算法,...
深度学习中的
正则化
:原理、方法与PyTorch实践(笔记)
2025-05-16 22:44
拉拉拉拉拉拉拉马的博客
正则化
通过向模型的优化目标(通常是损失函数)中添加一个额外的惩罚
项
(
正则化
项
)来实现。这个惩罚
项
用于量化模型的复杂度。因此,优化过程不仅要最小化模型在训练数据上的预测
误差
(经验风险),还要最小化这个...
正则化
线性模型:岭
回归
Ridge Regression(即线性
回归
的改进)、
la
sso
回归
(
La
sso
Regression)、弹性网络(E
la
stic Net)、Early Stopping
2021-08-11 09:34
あずにゃん的博客
人工智能
AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) 2.9
正则化
线性模型 学习目标 知道
正则化
中岭
回归
的线性模型 知道
正则化
中
la
sso
回归
的线性模型 知道
正则化
中弹性网络...
L1
正则化
算法系列:理论与应用
2025-07-22 04:44
运营的小事的博客
正则化
通过在损失函数中增加一个与模型复杂度相关的
项
来约束模型。对于一个线性模型,假设损失函数为均方
误差
(MSE),则L1
正则化
的目标函数可以表示为:其中,(&
la
mbda;) 是
正则化
强度的参数,(|θ|_1) 表示模型参数的L1...
正则化
技术总结
2021-08-20 00:17
Sais_Z的博客
正则化
方法总结概念
正则化
方法L2-NormL1-NormDropout思考 概念 过拟合与
正则化
在机器学习里,使用少量样本去拟合了所有没见过的样本, 我们叫这种现象为“过拟合”。另外,我们训练模型的数据不可避免的存在一些测量...
L1
正则化
和L2
正则化
2020-05-06 15:44
二胖_pro的博客
为什么加
正则化
项
可以防止过拟合? 从数学的角度来说,加
正则化
项
就相当于加约束条件,加了约束条件使很多的参数分量wi=0w_i=0wi=0(特征选择)从而降低模型复杂度,也就防止因为参数过多导致的过拟合现象 机...
机器学习高频知识点——1.
正则化
2024-03-28 16:50
异人无双的博客
正则化
技术,让你的模型不再“任性”过拟合!
【机器学习基础】第四十七课:[特征选择与稀疏学习]嵌入式选择与L1
正则化
2025-12-23 08:07
x-jeff的博客
L1
正则化
,L2
正则化
,岭
回归
,
LA
SSO
,近端梯度下降(PGD),连续函数,一致连续(均匀连续),利普希茨连续(Lipschitz continuity),利普希茨常数
python
正则化
调优_介绍一下
正则化
Regu
la
rization
2020-12-28 23:43
wiles super的博客
www.zhihu.comE
la
sticNet
回归
及机器学习
正则化
_
人工智能
_曾时明月-CSDN博客blog.csdn.net以下为个人对
正则化
Regu
la
rization是what, how to apply, where its come from, and its code 的拙见。如果有理
解
的不对...
Pytorch学习笔记(8):
正则化
(L1、L2、Dropout)与归一化(BN、LN、IN、GN)
2023-03-02 23:11
路人贾'ω'的博客
Pytorch学习笔记(8):
正则化
(L1、L2、Dropout)与归一化(BN、LN、IN、GN)超级详细!
ML基础100题:④优化理论+
正则化
(25道)
2026-04-01 21:17
白话机器学习的博客
ML优化理论与
正则化
25题摘要 梯度下降原理:通过计算损失函数梯度并沿反方向更新参数,逐步逼近最小值。核心公式θ_new=θ_old-α·&nab
la
;J(θ),学习率α控制步长。 SGD vs BGD:BGD使用全量数据计算梯度,稳定但慢;...
机器学习实战:如何用
正则化
方法
解
决数据共线性(附Python代码)
2025-08-14 03:27
ik678901234的博客
通过相关系数矩阵和方差膨胀因子(VIF)识别共线性,并重点介绍了岭
回归
和
LA
SSO
回归
两种
正则化
方法。文章提供了完整的Python代码实战,包括模型实现、参数调优及对比选型指南,帮助读者构建稳健、可
解
释的预测模型。
机器学习:线性
回归
之损失函数、正规方程、梯度下降、过拟合和欠拟合、
正则化
2021-07-16 13:43
示木007的博客
线性
回归
(Linear regression)是利用
回归
方程(函数)对一个或多个自变量(特征值)和因变量(目标值)
之间
关系进行建模的一种分析方式。 特点:只有一个自变量的情况称为单变量
回归
,多于一个自变量情况的叫做多元
回归
...
【机器学习-线性
回归
-4】线性
回归
中的最优
解
:从数学原理到实践应用
2025-04-27 20:09
AllenBright的博客
在线性
回归
中,最优
解
指的是能够最小化预测值与真实值
之间
差异的参数组合。损失函数其中m是样本数量。我们的目标就是找到使J(w)最小的w。
解
析
解
(闭式
解
)对于普通最小二乘
回归
(OLS),最优
解
可以通过正规方程(Normal...
机器学习-常用
回归
算法归纳(全网之最)
2021-10-28 18:14
WGS.的博客
Ridge
回归
La
sso
回归
Ridge
回归
岭
回归
和
la
sso
回归
的区别L1正则 & L2正则弹性网络
回归
贝叶斯岭
回归
Huber
回归
KNNSVMSVM最大间隔支持向量 & 支持向量平面寻找最大间隔SVRCART树随机森林GBDTboosting思想AdaBoost...
初识
人工智能
,一文读懂机器学习之逻辑
回归
知识文集(6)
2024-01-27 08:38
普修罗双战士的博客
方差(Variance)指的是模型的预测值在不同数据集上的波动程度,它表示了模型的稳定性和泛化能力。如果模型的方差较大,说明模型对训练数据的波动较敏感,容易出现过拟合(Overfitting)的情况。当模型的方差较小时...
动作控制中
回归
点估计为什么造成 模态塌缩(平均动作)? V
LA
中的模态探索和图文模型的模态探索有什么区别?详述模态坍缩的概念
2025-08-11 10:53
具身机器人曾小健的博客
L1 范数L2 范数在
回归
里我们用“残差”ei=yi−y^ie_i=y_i-\hat y_iei=yi−y^i 来做损失L1 损失(绝对
误差
和)平均化后就是L2 损失(
平方
误差
和)平均化后就是结论:在作为
误差
度量的语境里,“L1”≈“MAE”...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已结题
(查看结题原因)
4月23日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
4月7日


 分享
分享
 关注
关注
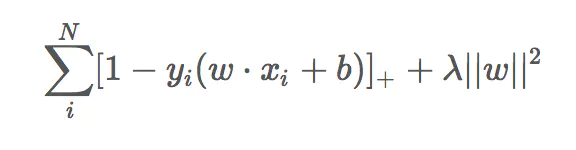
 已结题
(查看结题原因) 4月23日
已结题
(查看结题原因) 4月23日

