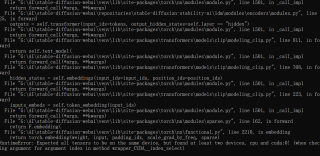
报错→RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select)
请问这个问题怎么解决呀?

 分享
分享
 关注
关注这个报错的原因是,你使用了既包含CPU张量又包含GPU张量的操作。在这种情况下,你需要确保所有张量都处于相同的设备上。
要解决这个问题,你可以使用.to(device)方法将所有张量(包括输入、权重、偏置等)都显式地移动到相同的设备上,如下面的例子所示:
import torch
# 判断是否支持GPU加速
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 构造示例模型
model = YourModel().to(device)
# 加载训练数据和标签,并将它们移动到同一个设备上
data, target = data.to(device), target.to(device)
# 前向传递
output = model(data)
# 执行损失函数计算
loss_fn = torch.nn.CrossEntropyLoss()
loss = loss_fn(output, target)
在以上示例中,我们首先判断是否支持GPU加速,然后使用.to(device)将模型移到与数据和目标张量相同的设备上。
如果你已经有了一个混合设备列表,则可以使用to()方法中的non_blocking=True参数来异步移动张量,以避免不必要的等待,如下所示:
tensor_list = [cpu_tensor1, cpu_tensor2, gpu_tensor1, gpu_tensor2]
devices = [torch.device('cpu'), torch.device('cpu'), torch.device('cuda'), torch.device('cuda')]
for tensor, device in zip(tensor_list, devices):
tensor.to(device=device, non_blocking=True)
除了使用.to()方法之外,你也可以使用.cuda()和.cpu()方法来移动张量,并检查拥有的设备,如下所示:
if your_tensor.is_cuda:
your_tensor = your_tensor.cpu()
在此例中,if语句会检查张量是否位于GPU上。如果是,它将使用.cpu()方法将其移到CPU上。
综上所述,根据你自己的情况和需求来移动张量到同一个设备上,可以避免这个报错。
分享 已结题
(查看结题原因) 5月28日
创建了问题
5月28日
已结题
(查看结题原因) 5月28日
创建了问题
5月28日


