
运行以下代码,发现存入npz文件内的图片是乱码,输出图在下方,已检查“数据集路径”,“图片尺寸”,“图片格式“均无问题。安装的库均为匹配版本
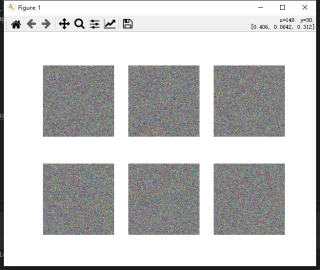
以下是保存数据集代码
from os import listdir
import numpy as np
from numpy import asarray
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
def load_images(path, size=(256, 256)):
data_list = list()
for filename in listdir(path):
pixels = load_img(path + filename, target_size=size)
pixels = img_to_array(pixels)
data_list.append(pixels)
return asarray(data_list)
# dataset path
path = '../hourse/horse2zebra/'
# load dataset A
dataA1 = load_images(path + 'trainA/')
dataA2 = load_images(path + 'testA/')
dataA = np.vstack((dataA1, dataA2))
print('Loaded dataA: ', dataA.shape)
# load dataset B
dataB1 = load_images(path + 'trainB/')
dataB2 = load_images(path + 'testB/')
dataB = np.vstack((dataB1, dataB2))
print('Loaded dataB: ', dataB.shape)
# save as compressed numpy array
filename = 'horse2zebra256.npz'
# np.savez_compressed(filename, dataA, dataB)
print('Saved dataset: ', filename)
# 查看horse2zebra_256.npz里的图片
from numpy import load
from matplotlib import pyplot
data = load(r'../hourse/horse2zebra256.npz')
dataA, dataB = data['arr_0'], data['arr_1']
print('Loaded: ', dataA.shape, dataB.shape)
n_samples = 3
for i in range(n_samples):
pyplot.subplot(2, n_samples, 1 + i)
pyplot.axis('off')
pyplot.imshow(dataA[i])
for i in range(n_samples):
pyplot.subplot(2, n_samples, 1 + n_samples + i)
pyplot.axis('off')
pyplot.imshow(dataB[i])
pyplot.show()
以下是创建npz文件代码
import numpy as np
# 创建需要存储的数据
dataA = np.random.rand(100, 256, 256, 3)
dataB = np.random.rand(100, 256, 256, 3)
# 存储数据到npz文件
np.savez('horse2zebra256.npz', arr_0=dataA, arr_1=dataB)







