yolov5中test.py运行报错,提示data错误不懂了,求在线了,朋友们帮解决一下!!
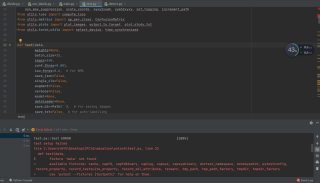

yolov5中test.py运行报错,提示data错误不懂了,求在线了,朋友们帮解决一下!!
 分享
分享
 关注
关注【相关推荐】
import os
import cv2
import argparse
import numpy as np
import tensorflow as tf
import yolo.config as cfg
from yolo.yolo_net import YOLONet
from utils.timer import Timer
# 用于网络测试
class Detector(object):
def __init__(self, net, weight_file):
self.net = net # yolov1网络
self.weights_file = weight_file # 检查点文件路径
self.classes = cfg.CLASSES # voc数据集的类别名
self.num_class = len(self.classes) # voc类别数
self.image_size = cfg.IMAGE_SIZE # 输入图像大小
self.cell_size = cfg.CELL_SIZE # 分成多个网格
self.boxes_per_cell = cfg.BOXES_PER_CELL # 每个网格里面有多少个边界框 B=2
self.threshold = cfg.THRESHOLD # 阈值参数
self.iou_threshold = cfg.IOU_THRESHOLD # IOU阈值参数
# # 将网络输出分离为类别和置信度以及边界框大小,输出维度为7*7*20 + 7*7*2+7*7*2*4=1470
self.boundary1 = self.cell_size * self.cell_size * self.num_class # 7*7*20
self.boundary2 = self.boundary1 +\
self.cell_size * self.cell_size * self.boxes_per_cell # 7*7*20 + 7*7*2
self.sess = tf.Session() # 开启会话
self.sess.run(tf.global_variables_initializer()) # 初始化全局变量
print('Restoring weights from: ' + self.weights_file)
self.saver = tf.train.Saver()
self.saver.restore(self.sess, self.weights_file) # 恢复训练得到的模型
# 将检测结果画到对应的图片上
def draw_result(self, img, result):
for i in range(len(result)): # 遍历所有的检测结果
x = int(result[i][1]) # x_center
y = int(result[i][2]) # y_center
w = int(result[i][3] / 2) # w/2
h = int(result[i][4] / 2) # h/2
# 绘制矩形框(目标边界框)矩形左上角,矩形右下角
cv2.rectangle(img, (x - w, y - h), (x + w, y + h), (0, 255, 0), 2)
# 绘制矩形框,用于存放类别名称,使用灰度填充
cv2.rectangle(img, (x - w, y - h - 20),
(x + w, y - h), (125, 125, 125), -1)
lineType = cv2.LINE_AA if cv2.__version__ > '3' else cv2.CV_AA # 线型
cv2.putText(
img, result[i][0] + ' : %.2f' % result[i][5],
(x - w + 5, y - h - 7), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 0, 0), 1, lineType) # 绘制文本信息,写上类别名和置信度
def detect(self, img):
img_h, img_w, _ = img.shape # 获取图片的宽和高
inputs = cv2.resize(img, (self.image_size, self.image_size)) # 图片缩放 [448,448,3]
inputs = cv2.cvtColor(inputs, cv2.COLOR_BGR2RGB).astype(np.float32) # 颜色转换 BGR -> RGB
inputs = (inputs / 255.0) * 2.0 - 1.0 # 归一化处理,[-1.0,1.0]
inputs = np.reshape(inputs, (1, self.image_size, self.image_size, 3)) # reshape [1,448,448,3]
result = self.detect_from_cvmat(inputs)[0] # 获取网络输出第一项(即第一张图片) [1,1470]
# 对检测结果的边界框进行缩放处理,一张图片可以有多个边界框
for i in range(len(result)):
# x_center,y_center,w,h都是真实值,分别表示预测边界框的中心坐标,宽,高
result[i][1] *= (1.0 * img_w / self.image_size) # x_center
result[i][2] *= (1.0 * img_h / self.image_size) # y_center
result[i][3] *= (1.0 * img_w / self.image_size) # w
result[i][4] *= (1.0 * img_h / self.image_size) # h
return result
# 运行yolo网络,开始检测
def detect_from_cvmat(self, inputs):
"""
inputs:输入数据 [None,448,448,3]
return : 返回目标检测的结果,每一个元素对应一个测试图片,每个元素包含着若干个边界框
"""
# 返回网络最后一层,激活函数处理之前的值,shape = [None,1470]
net_output = self.sess.run(self.net.logits,
feed_dict={self.net.images: inputs})
results = []
# 对网络输出每一行数据进行处理
for i in range(net_output.shape[0]):
results.append(self.interpret_output(net_output[i]))
return results # 返回处理后的结果
def interpret_output(self, output):
"""
对yolov1网络输出进行处理
args:
output :yolo网络输出的每一行数据,大小为[1470,]
0:7*7*20 表示的是预测类别
7*7*20 : 7*7*20 + 7*7*2 表示预测置信度,即预测的边界框与实际边界框之间的IOU
7*7*20 + 7*7*2 : 1470 表示预测边界框 目标中心是相对当前网格的,宽度和高度的开根号是相对于当前整张图片的(归一化)
return :
result : yolo网络目标检测到的边界框,list类型,每一个元素对应一个目标框
包含(类别名,x_center,y_center,w,h,置信度) 实际上这个置信度是yolo网络输出的置信度confidence和预测对应的类别概率的乘积
"""
probs = np.zeros((self.cell_size, self.cell_size,
self.boxes_per_cell, self.num_class)) # shape [7,7,2,20]
class_probs = np.reshape(
output[0:self.boundary1],
(self.cell_size, self.cell_size, self.num_class)) # 类别概率 [7,7,20]
scales = np.reshape(
output[self.boundary1:self.boundary2],
(self.cell_size, self.cell_size, self.boxes_per_cell)) # 置信度 [7,7,2]
boxes = np.reshape(
output[self.boundary2:],
(self.cell_size, self.cell_size, self.boxes_per_cell, 4)) # 边界框 [7,7,2,4]
offset = np.array( # [14,7] 每一行都是[0,1,2,3,4,5,6]
[np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell)
offset = np.transpose( # [7,7,2] 每一行都是[[0,0],[1,1],[2,2],[3,3],[4,4],[5,5],[6,6]]
np.reshape(
offset,
[self.boxes_per_cell, self.cell_size, self.cell_size]),
(1, 2, 0))
# 目标中心是相对于当前网格的
boxes[:, :, :, 0] += offset
boxes[:, :, :, 1] += np.transpose(offset, (1, 0, 2))
boxes[:, :, :, :2] = 1.0 * boxes[:, :, :, 0:2] / self.cell_size
# 宽度,高度相对于整张图片
boxes[:, :, :, 2:] = np.square(boxes[:, :, :, 2:])
boxes *= self.image_size # 转换成实际的边界框(没有归一化)
# 遍历每一个边界框的置信度
for i in range(self.boxes_per_cell):
# 遍历每一个类别
for j in range(self.num_class):
# 在测试时,乘以条件概率和单个盒子的置信度,这些分数编码了j类出现在框i中的概率以及预测框拟合目标的程度
probs[:, :, i, j] = np.multiply(
class_probs[:, :, j], scales[:, :, i])
# [7,7,2,20] 如果第i个边界框检测到类别j,且概率大于阈值,则[:,:,i,j] = 1
filter_mat_probs = np.array(probs >= self.threshold, dtype='bool')
# 返回filter_mat_probs非0值的索引,返回4个List,每个List长度为n,即检测到的边界框的个数
filter_mat_boxes = np.nonzero(filter_mat_probs)
# 获取检测到目标的边界框 [n,4] n表示边界框个数
boxes_filtered = boxes[filter_mat_boxes[0],
filter_mat_boxes[1], filter_mat_boxes[2]]
# 获取检测到目标的边界框的置信度 [n,]
probs_filtered = probs[filter_mat_probs]
# 获取检测到的目标的边界框对应的类别 [n,]
classes_num_filtered = np.argmax(
filter_mat_probs, axis=3)[
filter_mat_boxes[0], filter_mat_boxes[1], filter_mat_boxes[2]]
# 按照置信度倒序排序,返回对应的索引
argsort = np.array(np.argsort(probs_filtered))[::-1]
boxes_filtered = boxes_filtered[argsort]
probs_filtered = probs_filtered[argsort]
classes_num_filtered = classes_num_filtered[argsort]
for i in range(len(boxes_filtered)):
if probs_filtered[i] == 0:
continue
for j in range(i + 1, len(boxes_filtered)):
# 计算n个边界框,两两之间的IOU是否大于阈值,进行非极大抑制
if self.iou(boxes_filtered[i], boxes_filtered[j]) > self.iou_threshold:
probs_filtered[j] = 0.0
# 非极大抑制后的输出
filter_iou = np.array(probs_filtered > 0.0, dtype='bool')
boxes_filtered = boxes_filtered[filter_iou]
probs_filtered = probs_filtered[filter_iou]
classes_num_filtered = classes_num_filtered[filter_iou]
result = []
# 遍历每一框
for i in range(len(boxes_filtered)):
result.append(
[self.classes[classes_num_filtered[i]], # 类别名
boxes_filtered[i][0], # x_center
boxes_filtered[i][1], # y_center
boxes_filtered[i][2], # w
boxes_filtered[i][3], # h
probs_filtered[i]]) # 置信度
return result
def iou(self, box1, box2): # 计算两个边界框的IOU
tb = min(box1[0] + 0.5 * box1[2], box2[0] + 0.5 * box2[2]) - \
max(box1[0] - 0.5 * box1[2], box2[0] - 0.5 * box2[2]) # 公共部分的宽
lr = min(box1[1] + 0.5 * box1[3], box2[1] + 0.5 * box2[3]) - \
max(box1[1] - 0.5 * box1[3], box2[1] - 0.5 * box2[3]) # 公共部分的高
inter = 0 if tb < 0 or lr < 0 else tb * lr
return inter / (box1[2] * box1[3] + box2[2] * box2[3] - inter) # 返回IOU
def camera_detector(self, cap, wait=10):
"""打开摄像头,实时检测"""
detect_timer = Timer() # 测试时间
ret, _ = cap.read() # 读取一帧
while ret:
ret, frame = cap.read() # 读取一帧
detect_timer.tic() # 测试开始时间
result = self.detect(frame)
detect_timer.toc() # 测试结束时间
print('Average detecting time: {:.3f}s'.format(
detect_timer.average_time))
self.draw_result(frame, result) # 绘制边界框以及添加附加信息
# 显示
cv2.imshow('Camera', frame)
cv2.waitKey(wait)
ret, frame = cap.read() # 读取下一帧
def image_detector(self, imname, wait=0):
"""对图片进行检测"""
detect_timer = Timer() # 计时
image = cv2.imread(imname) # 读取图片
detect_timer.tic() # 测试开始计时
result = self.detect(image) # 开始测试,返回测试后的结果
detect_timer.toc() # 测试结束计时
print('Average detecting time: {:.3f}s'.format(
detect_timer.average_time))
self.draw_result(image, result)
cv2.imshow('Image', image)
cv2.waitKey(wait)
def main():
# 定义超参数
parser = argparse.ArgumentParser()
parser.add_argument('--weights', default="YOLO_small.ckpt", type=str) # 保存的训练好的模型
parser.add_argument('--weight_dir', default='weights', type=str)
parser.add_argument('--data_dir', default="data", type=str)
parser.add_argument('--gpu', default='0', type=str)
args = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu # 指定GPU进行测试
yolo = YOLONet(False) # 得到YOLOv1网络
weight_file = os.path.join(args.data_dir, args.weight_dir, args.weights) # 权重文件保存的路径
detector = Detector(yolo, weight_file)
# detect from camera
# cap = cv2.VideoCapture(-1)
# detector.camera_detector(cap)
# detect from image file
imname = 'test/person.jpg'
detector.image_detector(imname)
if __name__ == '__main__':
main()
以上便是个人对YOLOv1代码的理解,注释中如有不当的地方,还请各位指出!
分享 已结题
(查看结题原因) 10月13日
创建了问题
10月12日
已结题
(查看结题原因) 10月13日
创建了问题
10月12日

