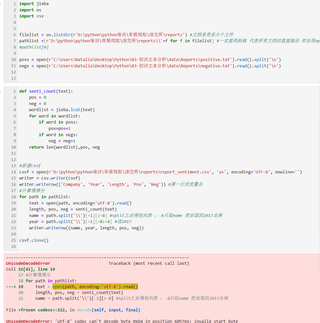

这个情感词分析的代码我之前用别人转给我们的txt统计出来是没问题的。但是我自己从深交所爬年报pdf转成txt,然后再用的这个感情词分析代码一直统计不了,一直出code的问题,想问下大家这要怎么解决

这个情感词分析的代码我之前用别人转给我们的txt统计出来是没问题的。但是我自己从深交所爬年报pdf转成txt,然后再用的这个感情词分析代码一直统计不了,一直出code的问题,想问下大家这要怎么解决
 分享
分享
 关注
关注引自强大而免费的微信小程序:皆我百晓生。
这个问题出现在使用Python解码Unicode字符时遇到了无效的起始字节。可能是因为文本文件的编码与指定的'utf-8'编码不匹配。
你可以尝试以下解决方法:
确认文本文件的编码:使用文本编辑器(例如Notepad++)打开txt文件,并查看文件编码格式。确保你在代码中使用与文件编码匹配的正确编码。例如,如果文件编码为'gbk',则应将代码中的'utf-8'更改为'gbk'。
使用错误处理:在使用open函数打开文本文件时,可以使用错误处理参数。例如,你可以尝试更改代码中的open函数为open(path, encoding='utf-8', errors='ignore')。这将忽略无效的字节而不抛出错误。
尝试不同的编码:如果上述方法都不起作用,尝试使用其他编码格式打开文件。可以尝试一些常用的编码格式,如'utf-8'、'gbk'、'latin-1'等。
检查文件完整性:确保从深交所爬取的pdf文件已正确转换为txt文件,并且文件没有损坏或损失任何字符。
希望以上解决方法能帮助你解决问题。如有需要,请提供更多信息以便我们提供更准确的帮助。
分享 系统已结题
11月27日
系统已结题
11月27日 已采纳回答
11月19日
创建了问题
11月18日
已采纳回答
11月19日
创建了问题
11月18日




