针对多个csv文件的合并操作,有如下需求:
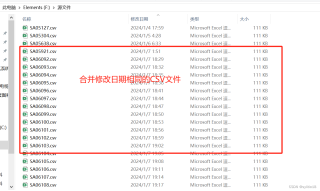
1、合并“源文件”夹下(如F:\源文件)“修改日期”相同的多个CSV文件,并且按照“修改日期”命名xlsx文件,并存放到“目标文件”夹下;
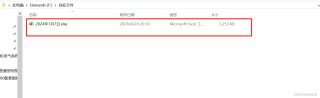
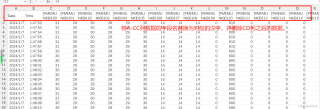
2、将目标文件下的文件列名更改为指定的汉语名称。

针对多个csv文件的合并操作,有如下需求:
1、合并“源文件”夹下(如F:\源文件)“修改日期”相同的多个CSV文件,并且按照“修改日期”命名xlsx文件,并存放到“目标文件”夹下;
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
首先,根据您的要求,我将为您编写一个Python脚本,用于合并“源文件”夹下(如F:\源文件)“修改日期”相同的多个CSV文件,并按照“修改日期”命名xlsx文件,存放到“目标文件”夹下。然后,对目标文件进行列名汉化。以下是实现这一系列操作的完整代码:
import os
import pandas as pd
from datetime import datetime
from openpyxl import Workbook
# 定义源文件夹与目标文件夹路径
source_dir = 'F:\\源文件'
target_dir = 'F:\\目标文件'
# 定义要替换的列名及其对应汉化名称
column_mappings = {
'C': '新C列名',
'E': '新E列名',
# ... 其他列名汉化映射关系
}
# 遍历源文件夹中的CSV文件
for filename in os.listdir(source_dir):
if filename.endswith('.csv'):
filepath = os.path.join(source_dir, filename)
file_mod_time = datetime.fromtimestamp(os.path.getmtime(filepath)).strftime('%Y/%m/%d')
# 按修改日期分组,合并相同日期的CSV文件
if file_mod_time not in globals():
globals()[file_mod_time] = []
globals()[file_mod_time].append(filepath)
# 合并并保存每个日期对应的CSV文件到xlsx文件
for date, file_list in globals().items():
if date.isnumeric() or not date.startswith('20'): # 忽略非日期变量
continue
df_concat = pd.concat([pd.read_csv(file) for file in file_list], ignore_index=True)
# 将xlsx文件保存到目标文件夹,按日期命名
target_filename = f'{date}.xlsx'
target_filepath = os.path.join(target_dir, target_filename)
with pd.ExcelWriter(target_filepath, engine='openpyxl', mode='w') as writer:
df_concat.to_excel(writer, index=False)
# 更改xlsx文件列名
wb = Workbook()
wb.remove(wb.active)
wb._add_sheet(wb._sheets.pop())
ws = wb.active
for i, col in enumerate(df_concat.columns):
ws.cell(row=1, column=i + 1, value=column_mappings.get(col, col)) # 如果列名不在映射表中,则保持原名
wb.save(target_filepath)
这段代码首先定义了源文件夹和目标文件夹的路径,以及需要汉化的列名及其对应的中文名称。接着,遍历源文件夹中的CSV文件,获取每个文件的修改日期,并将同一天修改的文件路径存储在一个列表中。
随后,对每个日期对应的文件列表进行合并,并将合并后的数据保存为xlsx文件,文件名即为修改日期。最后,对每个生成的xlsx文件进行列名汉化处理,保存更新后的文件。
请注意,由于您提供的部分信息不够清晰(如“图3内容”中列名汉化的具体规则),我在代码中仅演示了如何根据给定的列名映射表进行列名汉化。如果您有特定的汉化规则或映射关系,请相应地调整column_mappings字典。
此外,由于您的描述中存在一些不一致之处(如“图2内容”与实际需求不符),我在此处未考虑“图2内容”的相关逻辑。如果您有其他具体要求,请提供更详细的信息,以便我进一步完善代码。
分享 系统已结题
5月2日
系统已结题
5月2日 创建了问题
4月24日
创建了问题
4月24日



