在使用GAN进行信号生成时,判别器损失稳定了,但是生成器信号在稳定之后又开始剧烈波动,因为本人学的不太好所以想请教一下出现的原因
问题图像如下:
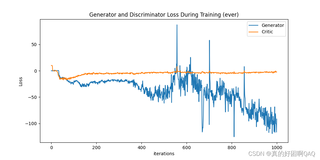
同时,在跑其原有的数据集时,其损失图像为这样,我感觉还是比较好的:
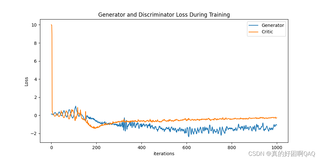
一开始是类似于双螺旋的结构在跑,但是能看出来很稳,之后在600轮就已经收敛的差不多了
想知道为什么我的没有这种类似双螺旋的损失过程
如果可以的话请多给我一些指导和相关知识

在使用GAN进行信号生成时,判别器损失稳定了,但是生成器信号在稳定之后又开始剧烈波动,因为本人学的不太好所以想请教一下出现的原因
问题图像如下:
如果可以的话请多给我一些指导和相关知识
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
在训练GAN(Generative Adversarial Networks)时,遇到生成器损失不稳定的情况是很常见的。这可能是由于多种原因导致的,包括但不限于以下几个方面:
解决这些问题的一种方法是尝试调整训练参数,例如降低学习率,增加训练步数,或者改变优化器。你也可以考虑使用不同的GAN变种,比如Wasserstein GAN(WGAN)或者Least Squares GAN(LSGAN),这些变种通常具有更好的收敛性和稳定性。
为了帮助你更好地理解并调试这个问题,这里有一个基本的PyTorch实现的Wasserstein GAN的示例,你可以对比你的代码,看看是否有可改进的地方:
import torch
from torch import nn, optim
from torchvision.utils import save_image
from torchvision import transforms, datasets
# 假设你已经有了定义好的 Generator 和 Discriminator 类
class Generator(nn.Module):
def __init__(self):
...
class Discriminator(nn.Module):
def __init__(self):
...
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 定义优化器
generator_optimizer = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
discriminator_optimizer = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 定义损失函数
criterion = nn.BCEWithLogitsLoss()
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True)
num_epochs = 200
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(dataloader):
real_images = real_images.to(device)
# 训练 Discriminator
discriminator.zero_grad()
real_labels = torch.ones(real_images.size(0)).to(device)
fake_labels = torch.zeros(real_images.size(0)).to(device)
real_predictions = discriminator(real_images).view(-1)
fake_images = generator(torch.randn_like(real_images)).detach()
fake_predictions = discriminator(fake_images).view(-1)
d_loss_real = criterion(real_predictions, real_labels)
d_loss_fake = criterion(fake_predictions, fake_labels)
d_loss = (d_loss_real + d_loss_fake) / 2
d_loss.backward()
discriminator_optimizer.step()
# 训练 Generator
generator.zero_grad()
fake_labels.fill_(1)
fake_predictions = discriminator(generator(torch.randn_like(real_images))).view(-1)
g_loss = criterion(fake_predictions, fake_labels)
g_loss.backward()
generator_optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], D loss: {d_loss.item():.4f}, G loss: {g_loss.item():.4f}')
# 在训练结束后保存一些生成的样本
with torch.no_grad():
z = torch.randn(64, 100).to(device)
generated_images = generator(z)
save_image(generated_images, 'generated_images.png', normalize=True)
在这个例子中,我们使用的是Wasserstein距离作为判别器的目标函数,而不是传统的二元交叉熵。这种损失函数通常会带来更平滑的训练过程。同时,注意检查你的代码中是否正确地实现了梯度反转操作,这对于WGAN来说至关重要。
此外,为了得到类似双螺旋的损失曲线,你需要定期记录和绘制损失。你可以创建一个CSV文件来存储每一步的损失值,然后使用Matplotlib或者其他可视化库来绘制它们。这将帮助你理解训练过程中的动态行为。
分享 创建了问题
4月28日
创建了问题
4月28日


