SHREC'17是动态手势数据集,其目录结构如下
├── display_gesture.m # MATLAB显示一个序列的脚本
├── display_sequence.py # python显示一个序列的脚本(依赖Scipy, Numpy and Matplotlib)
├── gesture_1 # 姿势id
│ ├── finger_1 # 手指id:单个指头(finger_1);整个手部(finger_2)
│ │ ├── subject_1 # 参与者id
│ │ │ ├── essai_1 # 序列id
│ │ │ │ ├── 0_depth.png # 第1帧的深度图
│ │ │ │ ├── 2_depth.png
│ │ │ │ ...
│ │ │ │ ├── N-1_depth.png # 第N帧的深度图
│ │ │ │ ├── general_informations.txt # shape=(N,5)为全部N帧中手部区域所在矩形框,每一行为(i, x, y, width, height)
│ │ │ │ ├── skeletons_image.txt # shape=(N,44)为全部N帧中2D深度图像中22个手关节的二维坐标
│ │ │ │ └── skeletons_world.txt # shape=(N,66)为全部N帧中3D世界坐标系下22个手关节的三维坐标
│ │ │ ├── essai_2
│ │ │ ...
│ │ │ └── essai_5
│ │ ├── subject_2
│ │ ...
│ │ └── subject_20
│ └── finger_2
├── gesture_2
...
├── gesture_14
├── test_gestures.txt # 训练序列的信息(1960行)格式为:id_gesture id_finger id_subject id_essai 14_labels 28_labels size_sequence
└── train_gestures.txt # 测试序列的信息(840行)
另外我自己将其里面的txt格式文件转换为了对应的json格式文件,即 test_gestures.json与train_gestures.json就放在那俩txt的后面,使用ST-GCN自带的tools里面的kinetics_gendata.py将json转换为npy与pkl时遇到问题,下面是转换代码:
import os
import sys
import pickle
import argparse
import json
import numpy as np
from numpy.lib.format import open_memmap
sys.path.append(
os.path.abspath(os.path.join(os.path.dirname(__file__), os.path.pardir)))
from feeder.feeder_kinetics import Feeder_kinetics
toolbar_width = 30
def print_toolbar(rate, annotation=''):
# setup toolbar
sys.stdout.write("{}[".format(annotation))
for i in range(toolbar_width):
if i * 1.0 / toolbar_width > rate:
sys.stdout.write(' ')
else:
sys.stdout.write('-')
sys.stdout.flush()
sys.stdout.write(']\r')
def end_toolbar():
sys.stdout.write("\n")
def gendata(
data_path,
label_path,
data_out_path,
label_out_path,
num_person_in=1, #observe the first 5 persons ----------------------------------------
num_person_out=1, #then choose 2 persons with the highest score -------------------
max_frame=300):
feeder = Feeder_kinetics(
data_path=data_path,
label_path=label_path,
num_person_in=num_person_in,
num_person_out=num_person_out,
window_size=max_frame)
sample_name = feeder.sample_name
sample_label = []
fp = open_memmap(
data_out_path,
dtype='float32',
mode='w+',
shape=(len(sample_name), 3, max_frame, 22, num_person_out))#---------------------------------------------------------
for i, s in enumerate(sample_name):
data, label = feeder[i]
print_toolbar(i * 1.0 / len(sample_name),
'({:>5}/{:<5}) Processing data: '.format(
i + 1, len(sample_name)))
fp[i, :, 0:data.shape[1], :, :] = data
sample_label.append(label)
with open(label_out_path, 'wb') as f:
pickle.dump((sample_name, list(sample_label)), f)
if __name__ == '__main__':#-------------------
parser = argparse.ArgumentParser(
description='SHREC Hand Gesture Data Converter.')
parser.add_argument(
'--data_path', default='data/HandGestureDataset_SHREC2017')
parser.add_argument(
'--out_folder', default='data/Kinetics/kinetics-skeleton')
arg = parser.parse_args()
part = ['train', 'val']
for p in part:
data_path = '{}/kinetics_{}'.format(arg.data_path, p)
label_path = '{}/kinetics_{}_label.json'.format(arg.data_path, p)
data_out_path = '{}/{}_data.npy'.format(arg.out_folder, p)
label_out_path = '{}/{}_label.pkl'.format(arg.out_folder, p)
if not os.path.exists(arg.out_folder):
os.makedirs(arg.out_folder)
gendata(data_path, label_path, data_out_path, label_out_path)
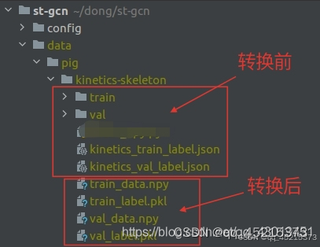
原来ST-GCN这个转换代码对应kinetics-skeleton数据集,这个数据集是明确将train与test分开成两个文件夹的,但是我这个数据集只能依靠txt或者json里面的内容来区分训练集与验证集,所以在这串代码里的data_path和label_path就不会写了,问了chatgpt给出的代码也不太能运行好。所以想请问,到底应该怎么写呢,万分感谢!
if __name__ == '__main__':#-------------------
parser = argparse.ArgumentParser(
description='SHREC Hand Gesture Data Converter.')
parser.add_argument(
'--data_path', default='data/HandGestureDataset_SHREC2017')
parser.add_argument(
'--out_folder', default='data/Kinetics/kinetics-skeleton')
arg = parser.parse_args()
part = ['train', 'val']
for p in part:
data_path = '{}/kinetics_{}'.format(arg.data_path, p)
label_path = '{}/kinetics_{}_label.json'.format(arg.data_path, p)
data_out_path = '{}/{}_data.npy'.format(arg.out_folder, p)
label_out_path = '{}/{}_label.pkl'.format(arg.out_folder, p)
if not os.path.exists(arg.out_folder):
os.makedirs(arg.out_folder)
gendata(data_path, label_path, data_out_path, label_out_path)
附图,原本来的 kinetics-skeleton数据集格式,是csdn上某位老哥帖子里的图,不妥删。