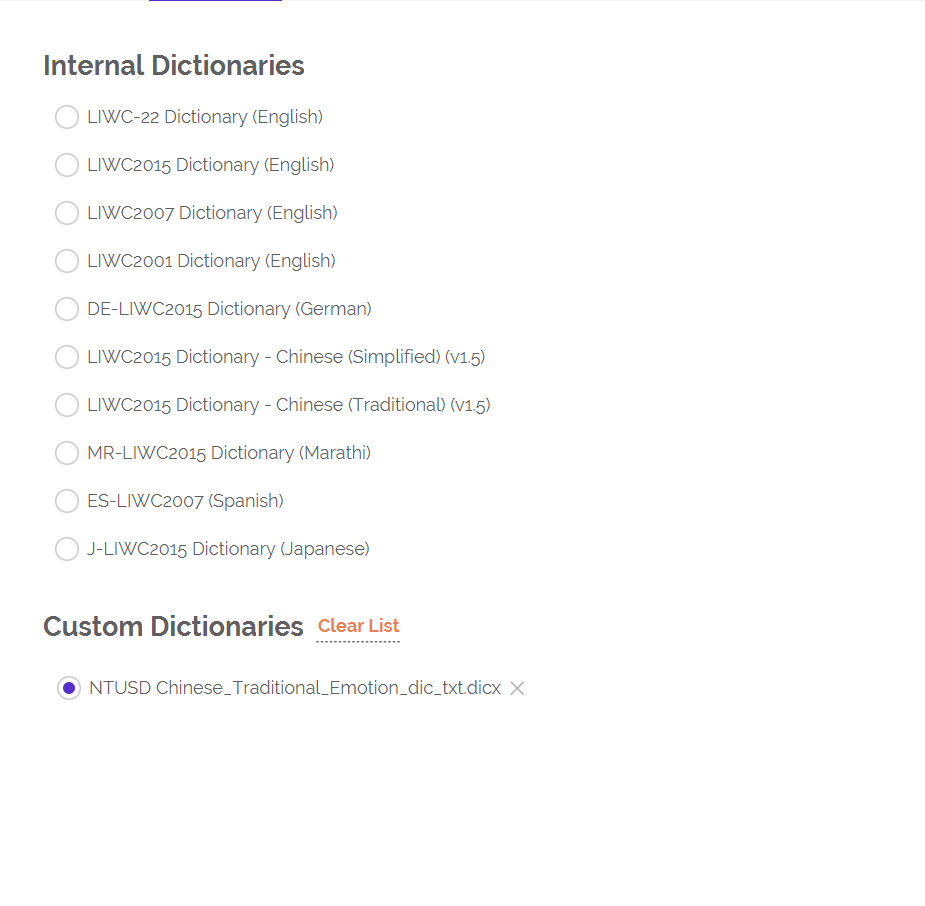
我现在要对一段繁体中文文本进行分析。首先,我用软件提供的繁体中文词典进行分析,发现它的WPS有200多,(如图一)这个数据肯定有问题,不可能每个句子平均有200多个词。但我文本里明明有句号,这是为什么啊?还有后面的,我用了台湾大学的简体字词典,并且把它变成了繁体字,自己做了一个词典(如图四)。但在分析中,发现Dic为0,这是什么意思呀?并且也没有显示posemo和negemo,这是为什么呢?请问怎么解决呢?请帮帮我!谢谢!
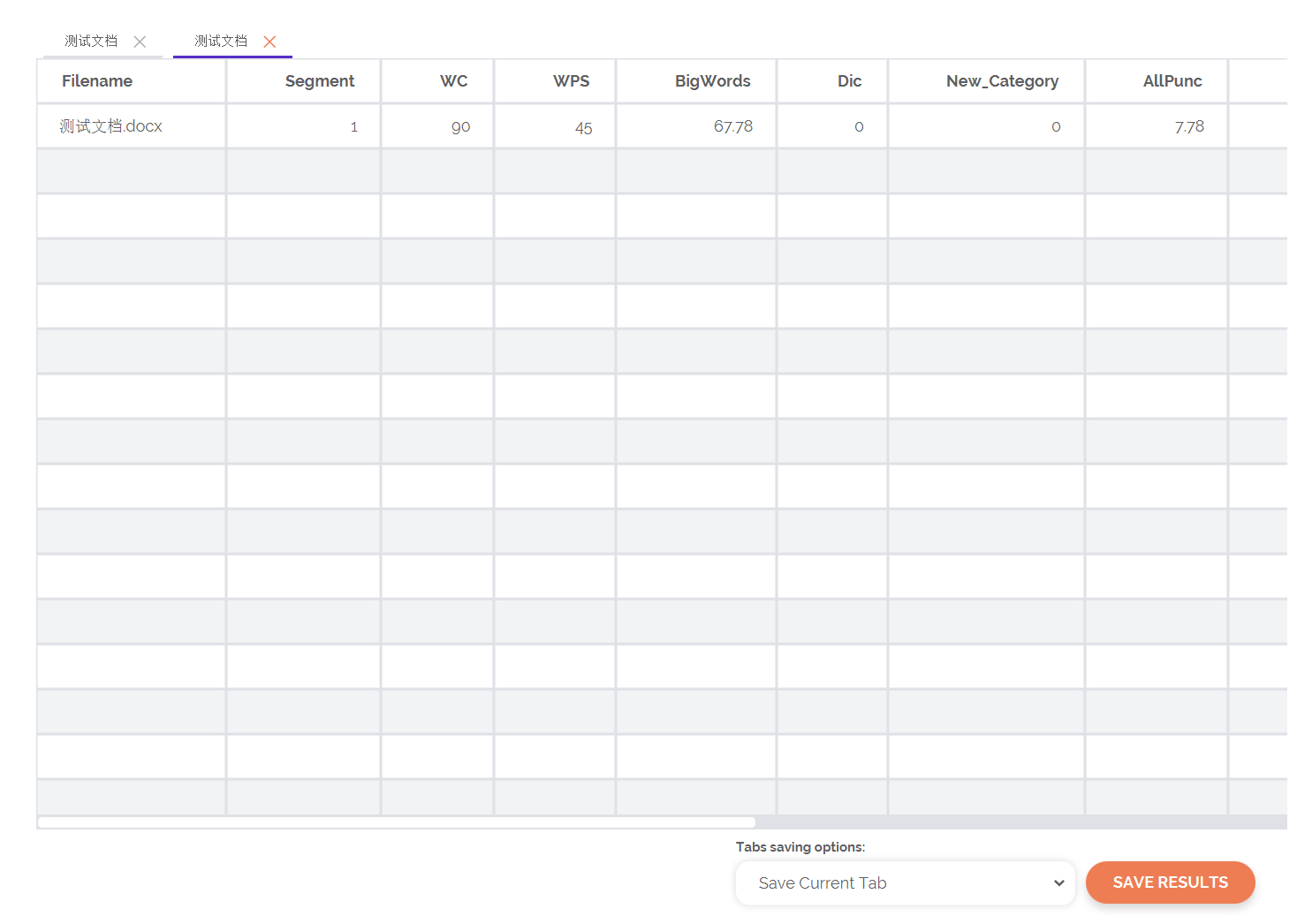
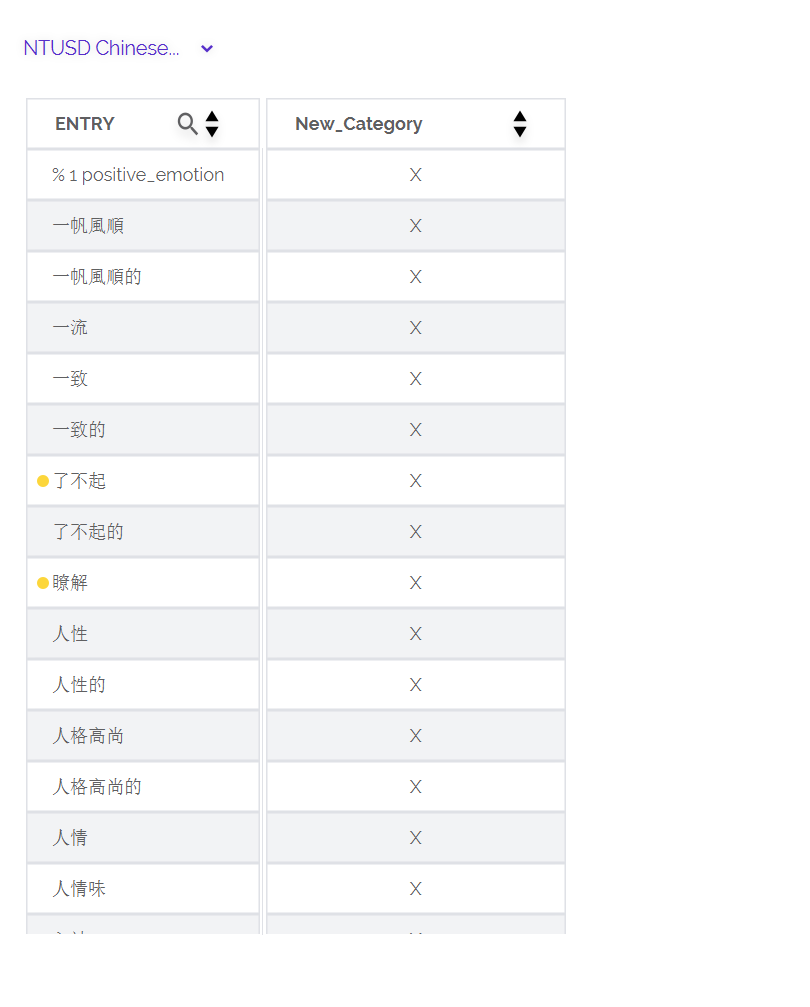
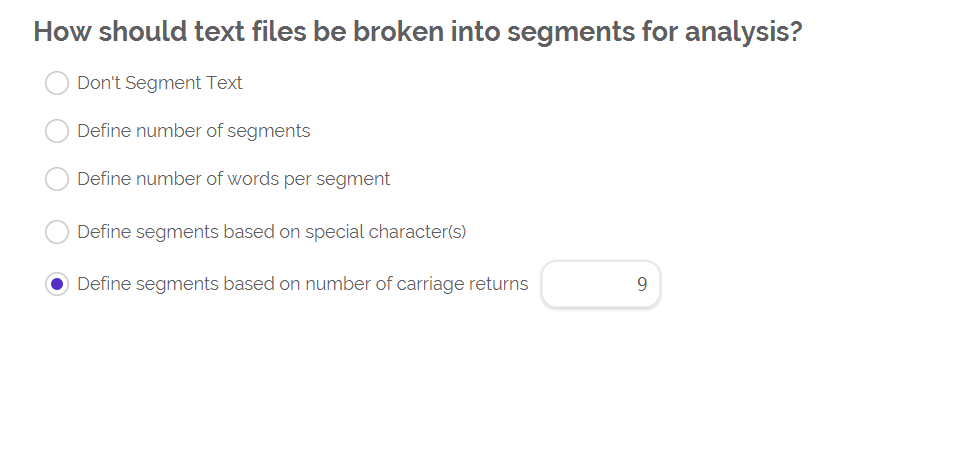

我现在要对一段繁体中文文本进行分析。首先,我用软件提供的繁体中文词典进行分析,发现它的WPS有200多,(如图一)这个数据肯定有问题,不可能每个句子平均有200多个词。但我文本里明明有句号,这是为什么啊?还有后面的,我用了台湾大学的简体字词典,并且把它变成了繁体字,自己做了一个词典(如图四)。但在分析中,发现Dic为0,这是什么意思呀?并且也没有显示posemo和negemo,这是为什么呢?请问怎么解决呢?请帮帮我!谢谢!
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
你遇到的问题是 LIWC 词频分析统计中 WPS(Word Per Sentence)数值过高的问题。 LIWC 是一种常用的文本分析工具,用于计算文本中的词频、句子结构等特征。
在你的情况下,可能是 LIWC 对繁体中文文本的处理方式导致的。 LIWC 可能将繁体中文文本中的特殊字符(如标点符号、括号等)作为单独的词语,导致 WPS 数值的增加。
为了解决这个问题,你可以尝试以下几种方法:
需要注意的是,LIWC 的词频分析结果可能会受到文本的格式和编码方式的影响。因此,在进行词频分析时,需要确保文本的格式和编码方式正确。
分享 创建了问题
4月16日
创建了问题
4月16日


