
用随机森林对一个特征集进行七分类,但得到的混淆矩阵长这样,是存在参数问题吗
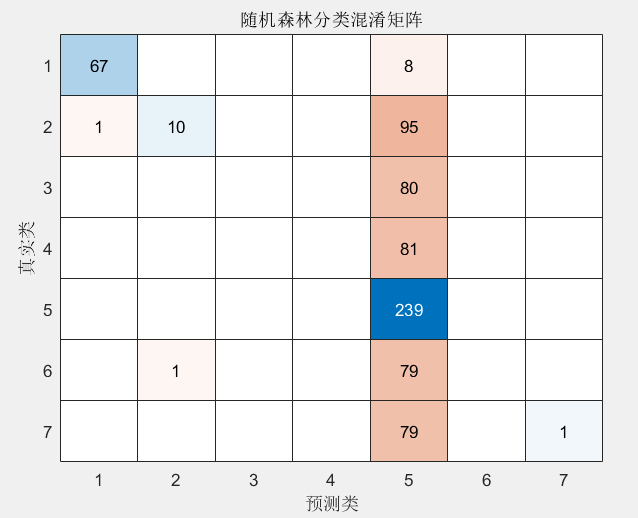
已做过归一化处理,以下是模型参数:
options = struct('Method', 'classification', 'NumTrees',200, ...%增加树的数量
'OOBPrediction', 'on', 'MinLeafSize', 20,...%增大叶子节点大小
'NumPredictorsToSample', 9,...%调整分裂时随机选取的特征数
'Prior', 'empirical'); % 启用类别权重)
model = TreeBagger(options.NumTrees, X_train, Y_train, ...
'OOBPredictorImportance', 'on', ...
'MinLeafSize', options.MinLeafSize,...
'NumPredictorsToSample', options.NumPredictorsToSample,...
'Prior', options.Prior); % 添加类别权重);





