baseline是yolov12,优化器用的SGD,close_mosaic=10
我用的DEIM-n,我看deim优化器用的AdamW,且轮次是160,如果我想设的和我的baseline一样用300,train_dataloader怎么设呢,有请帮我解答一下,感谢了。


baseline是yolov12,优化器用的SGD,close_mosaic=10
我用的DEIM-n,我看deim优化器用的AdamW,且轮次是160,如果我想设的和我的baseline一样用300,train_dataloader怎么设呢,有请帮我解答一下,感谢了。
 分享
分享
我曾经遇到过类似的问题,当时也是在做目标检测模型的对比实验,需要协调不同算法的参数设置。结合你提到的DEIM与YOLOv12对比实验需求,以下是具体分析和解决方案:
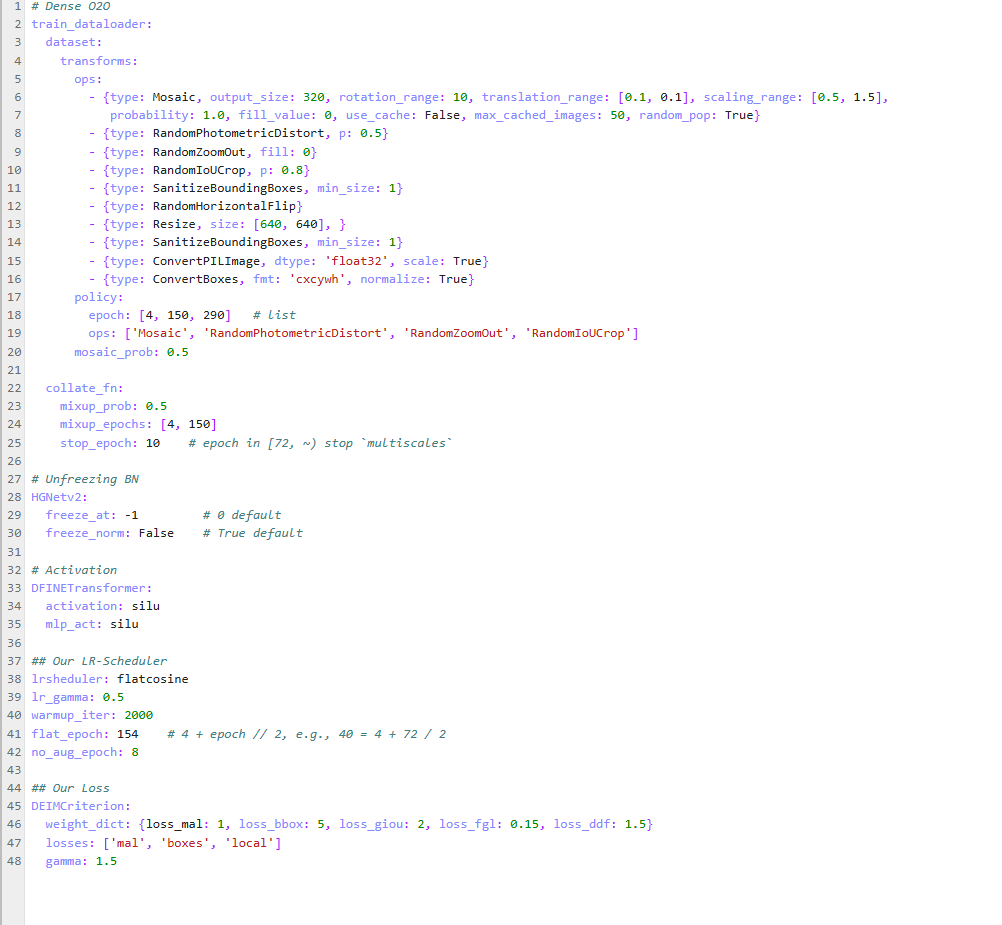
你的核心需求是:在DEIM-n模型中复用Baseline(YOLOv12)的训练配置(优化器SGD、300轮次),同时调整数据加载器参数。当前困惑点集中在优化器选择冲突(DEIM默认AdamW,Baseline用SGD)和训练轮次、数据增强策略的同步调整。
核心思路:沿用DEIM原生优化器配置,仅修改训练轮次和数据加载器参数,确保除优化器外的其他配置与Baseline对齐,便于公平对比。
关键调整步骤:
num_epochs从160改为300(需检查代码中所有涉及轮次的参数,如学习率调度器的flat_epoch、数据增强的epoch区间等)。train_dataloader的total_batch_size、num_workers与Baseline一致(当前配置为64和8,若Baseline相同则无需修改)。mosaic_epochs、stop_epoch等,使其覆盖300轮次范围。部分代码示例:
# 修改训练轮次
config.train.num_epochs = 300 # 全局轮次
config.lr_scheduler.flat_epoch = 154 # 若原逻辑为flat_epoch=4+epoch//2,需重新计算:4+300//2=154,与原配置一致
config.data_aug.stop_epoch = 290 # 确保数据增强在300轮前结束
# 数据加载器参数(若需调整)
config.train_dataloader.total_batch_size = 64 # 与Baseline一致
config.train_dataloader.num_workers = 8
核心思路:为了严格控制变量(仅对比是否使用DEIM数据增强),将DEIM的优化器改为与Baseline相同的SGD,其他参数(轮次、数据加载器)完全对齐。
关键调整步骤:
optimizer.type从AdamW改为SGD。部分代码示例:
# 替换为SGD优化器
config.optimizer.type = "SGD"
config.optimizer.params = [
{
"params": "^(?=.*backbone)(?!.*norm|bn).*$",
"lr": 0.001, # 假设Baseline的SGD初始学习率为0.001
"momentum": 0.9, # 添加SGD特有参数
"weight_decay": 0.0001
},
# 其他参数组按类似逻辑调整,注意SGD无需betas参数
]
# 固定轮次和数据加载器
config.train.num_epochs = 300
config.train_dataloader = baseline_train_dataloader_config # 直接引用Baseline的数据加载器配置
推荐理由:
执行注意事项:
DEIMCriterion的权重参数)完全一致。以上是针对你问题的详细分析和解决方案。建议优先尝试方案1,若需严格控制优化器变量,再考虑方案2。如果在代码实现中遇到具体问题(如学习率调度器适配、数据增强参数冲突),可以继续留言提供更多细节,我会进一步协助调试。请楼主采纳,如有疑问随时沟通!
分享 【论文翻译】YOLO26: KEY ARCHITECTURAL ENHANCEMENTS AND PERFORMANCE BENCHMARKING FOR REAL-TIME OBJECT DETEC
【论文翻译】YOLO26: KEY ARCHITECTURAL ENHANCEMENTS AND PERFORMANCE BENCHMARKING FOR REAL-TIME OBJECT DETEC 创建了问题
5月22日
创建了问题
5月22日
