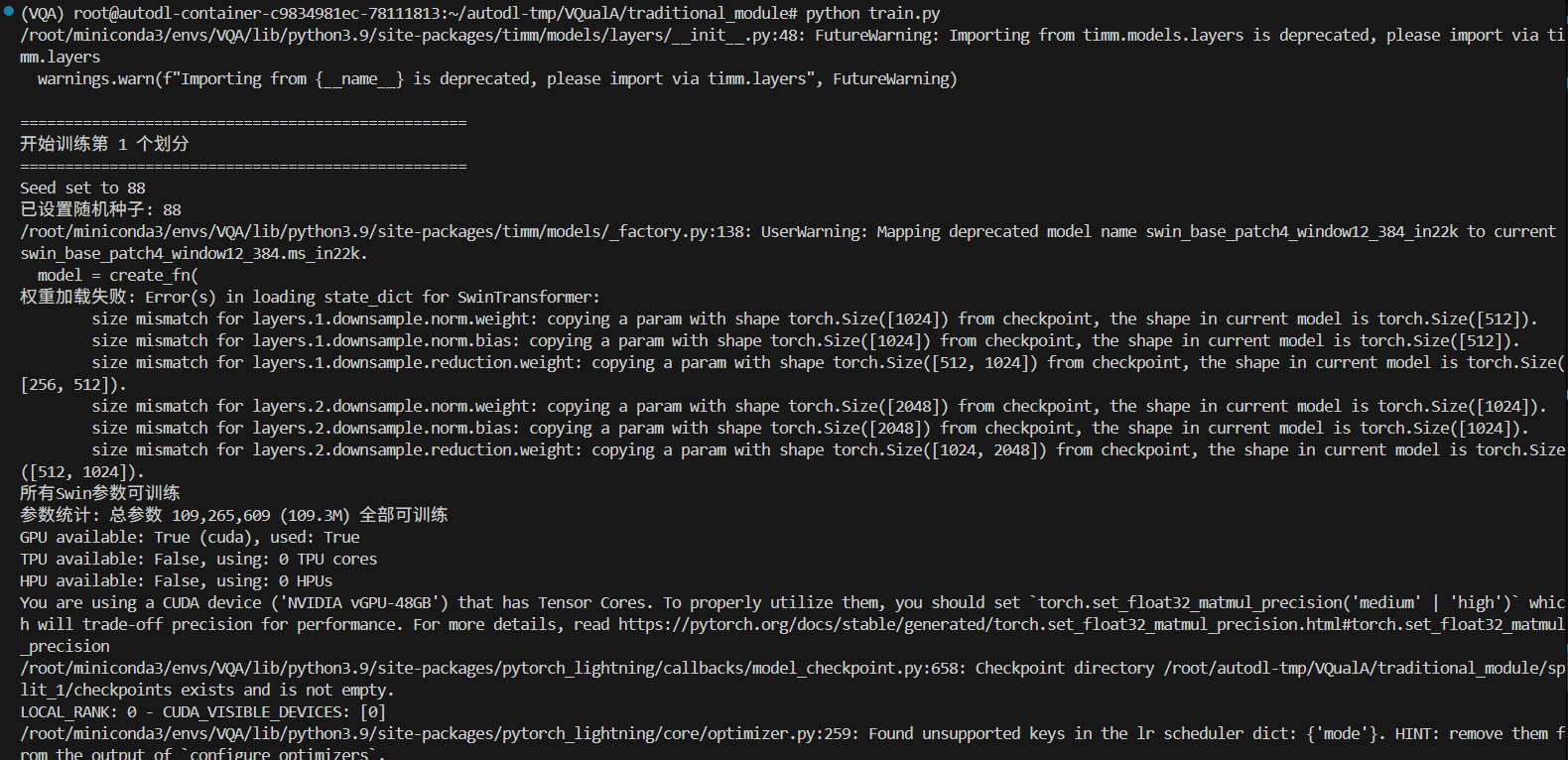
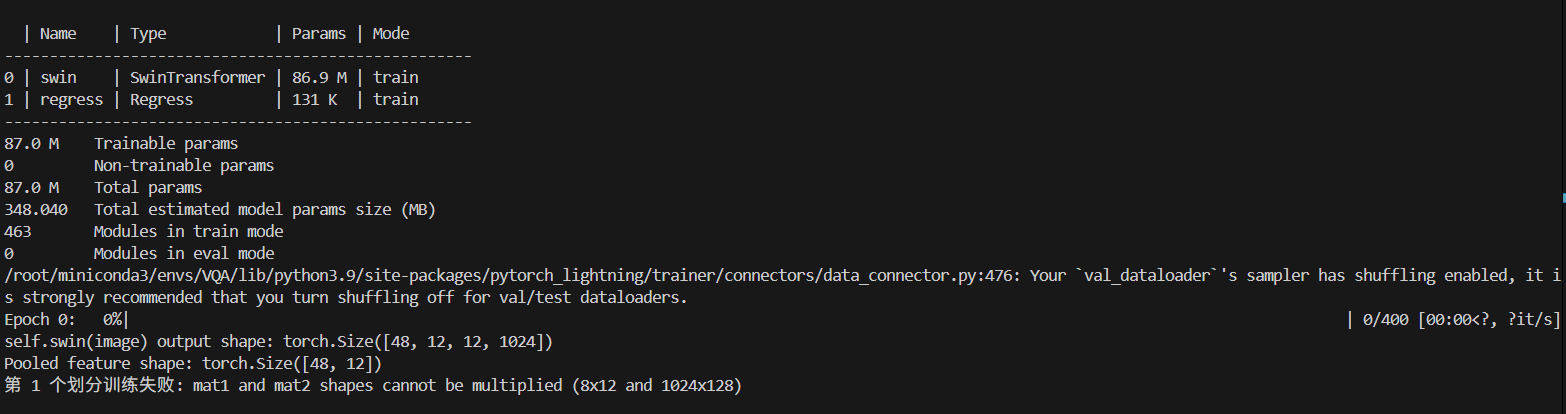
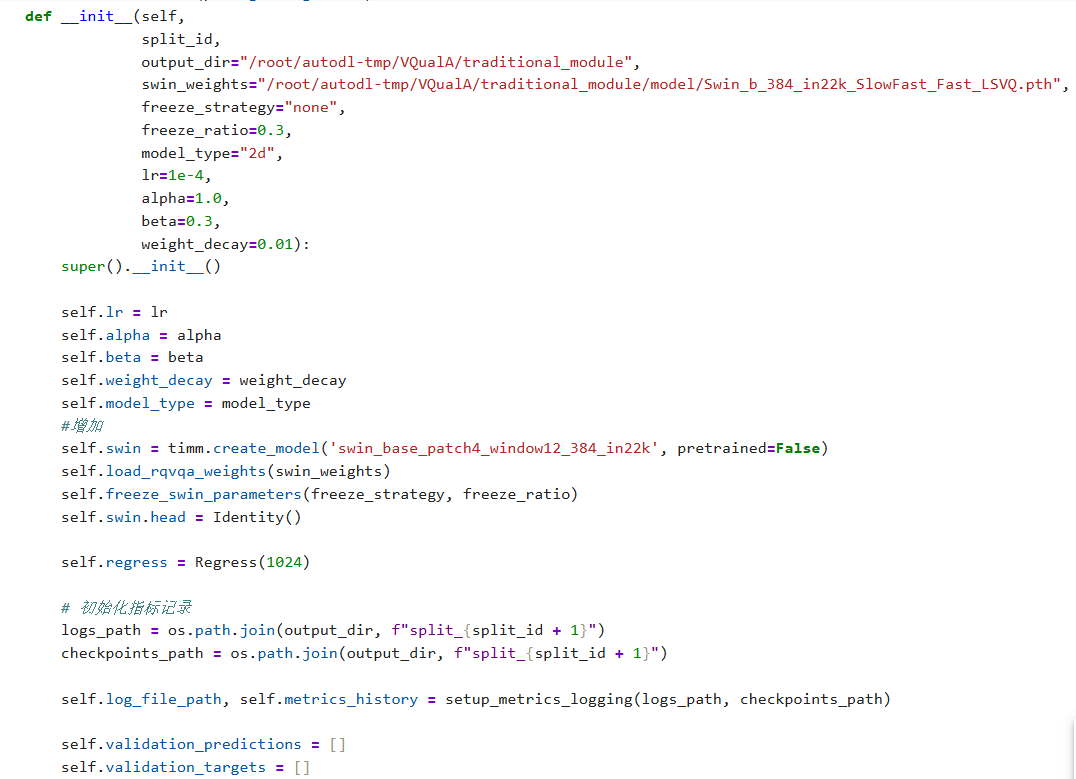
这个报错是什么意思呀,该如何去修改我的代码下面是我的部分代码截图,使用的是预训练的权重,想使用这个预训练的模型进行数据训练,感谢大家了,谢谢大家的回答


 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
你提到的报错信息没有直接给出,因此我需要根据你提供的上下文进行推测。从你的描述来看,你在使用预训练模型权重进行训练时遇到了问题,可能是以下几种情况之一:
维度不匹配(Shape Mismatch)
Expected input batch_size (x) to match model's expected batch_size (y)参数不匹配(Parameter Mismatch)
size mismatch for ...冻结层未正确设置(Freezing Layers)
requires_grad=False,但你想更新这些层。优化器或损失函数设置错误
TypeError: 'NoneType' object is not callable设备不匹配(CPU vs GPU)
RuntimeError: Expected all tensors to be on the same device为了更准确地帮助你解决问题,请提供以下信息:
torch.hub.load, from_pretrained, load_state_dict 等)# 示例:检查输入形状是否符合模型预期
print("Input shape:", inputs.shape)
print("Model input size:", model.input_shape)
如果发现维度不一致,可以调整输入数据的格式(如 reshape 或 padding)。
# 加载预训练模型
model = torchvision.models.resnet18(pretrained=True)
# 如果你自定义了模型结构,要确保它与预训练模型结构一致
# 否则需要手动加载权重
state_dict = torch.load('pretrained_weights.pth')
model.load_state_dict(state_dict, strict=False)
如果出现
KeyError或size mismatch,说明权重和模型结构不一致。你需要检查模型定义是否与预训练权重一致。
model.train() # 设置为训练模式
# 如果你只想训练部分层(如最后几层)
for param in model.parameters():
param.requires_grad = False # 冻结所有层
# 解冻特定层(如全连接层)
for param in model.fc.parameters():
param.requires_grad = True
如果你希望微调整个模型,不要冻结任何层。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 输入数据也要移到同一设备
inputs = inputs.to(device)
labels = labels.to(device)
如果模型在GPU上而数据在CPU上,会报错。确保两者在同一设备上。
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
如果优化器没有传入
model.parameters(),或者损失函数未定义,会导致运行时错误。
| 问题 | 原因 | 解决方案 |
|------|------|----------|
| 维度不匹配 | 输入数据形状与模型不一致 | 调整输入数据格式或模型结构 |
| 权重不匹配 | 预训练权重与模型结构不一致 | 检查模型定义,使用 strict=False 加载权重 |
| 冻结层错误 | 未正确设置梯度 | 使用 requires_grad 控制是否训练某层 |
| 设备不一致 | 模型和数据不在同一设备 | 将模型和数据都移动到同一设备(CPU/GPU) |
| 优化器/损失错误 | 未正确初始化 | 确保 optimizer 和 loss 函数正确初始化 |
如果你能提供具体的错误信息或代码片段,我可以进一步帮你分析并给出修改后的代码。欢迎补充!
分享 创建了问题
7月15日
创建了问题
7月15日


