单纯的识别这盒子上的数字,本来想一次识别多个训练的这个模型,但应用发现准确率不高,是距离问题吗?,原先训练周期更大情况下训练集测试集都有近90%准确率。
如果我改成固定位每次识别上下两个数字,或者模板匹配,会不会更准确一些?
希望可以解答一下用edgeimplus训练时的注意 事项和如何训练能准确些。
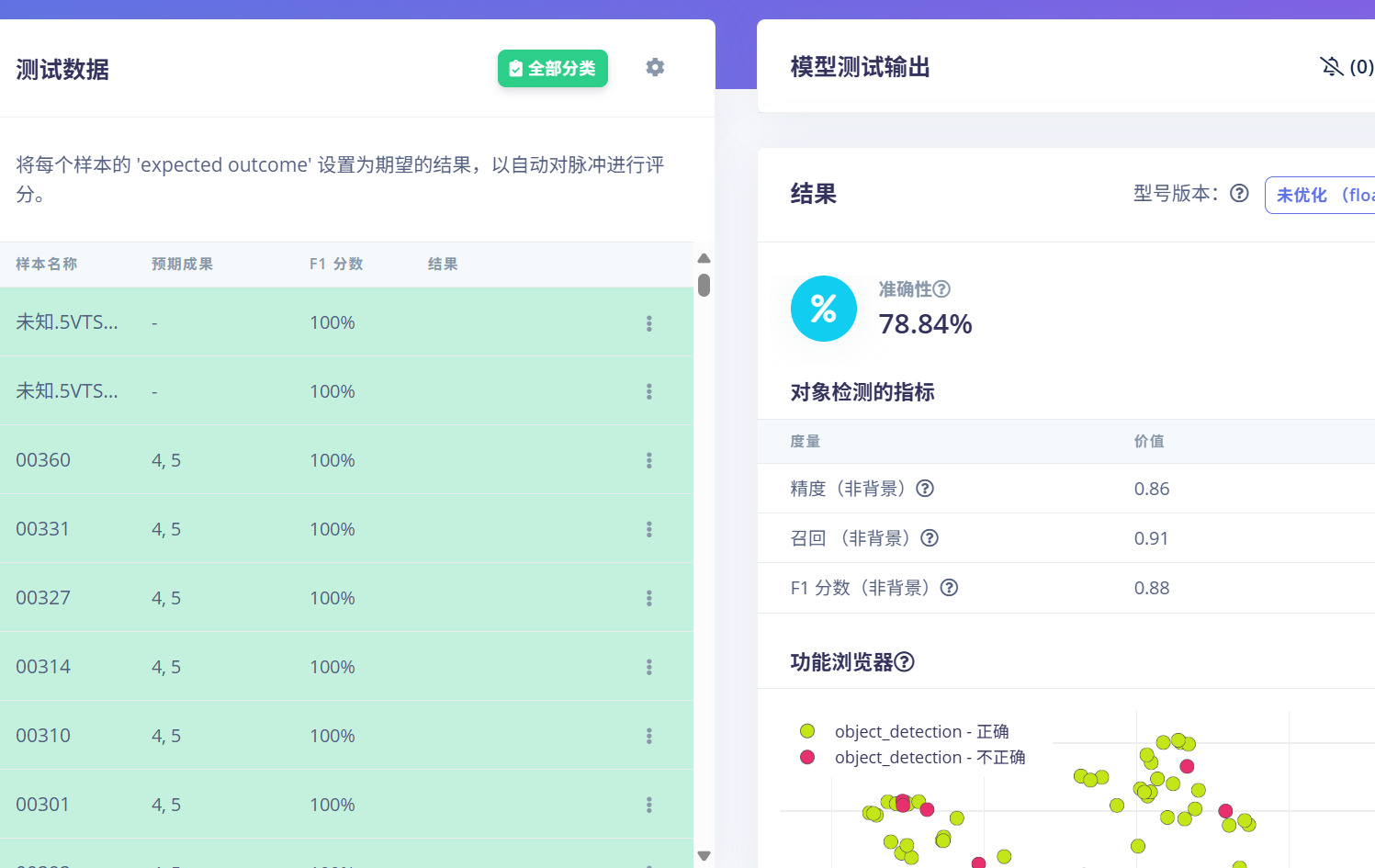

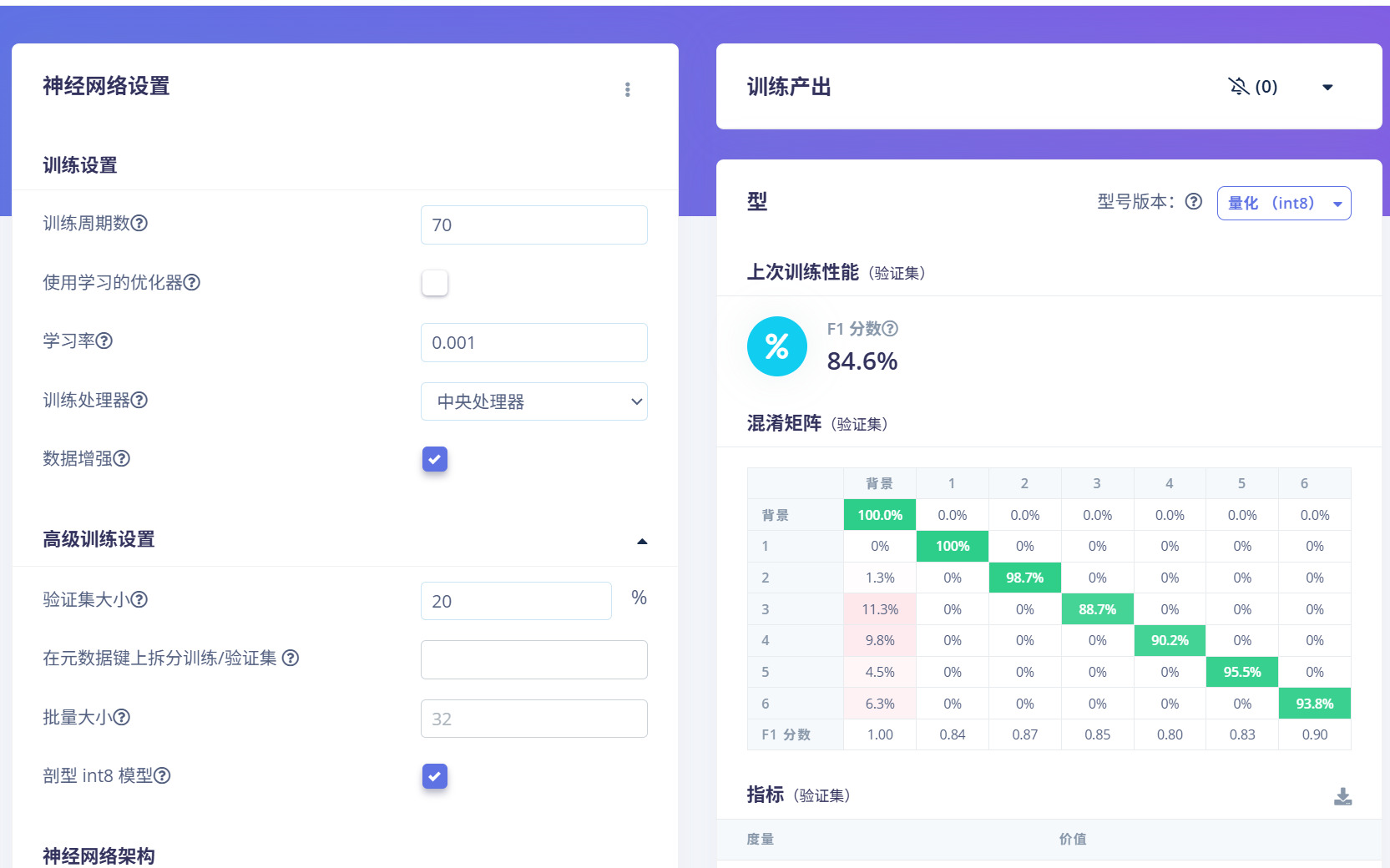

单纯的识别这盒子上的数字,本来想一次识别多个训练的这个模型,但应用发现准确率不高,是距离问题吗?,原先训练周期更大情况下训练集测试集都有近90%准确率。
如果我改成固定位每次识别上下两个数字,或者模板匹配,会不会更准确一些?
希望可以解答一下用edgeimplus训练时的注意 事项和如何训练能准确些。
 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
你提到的问题非常常见,尤其是在使用 OpenMV 或类似嵌入式视觉系统进行图像识别时。虽然在训练阶段(如使用 EdgeImpulse)模型的训练准确率和测试准确率都较高,但在实际部署中却出现识别错误的情况。这可能涉及多个因素,下面我将详细分析原因,并提供解决方案、注意事项以及优化建议。
重点提示: 训练数据要尽可能贴近真实应用场景!
示例代码(Python)(用于训练前的数据增强):
from PIL import Image, ImageOps
def augment_image(image_path):
img = Image.open(image_path)
# 翻转
flipped_img = ImageOps.mirror(img)
flipped_img.save("flipped_" + image_path)
# 旋转
rotated_img = img.rotate(90)
rotated_img.save("rotated_" + image_path)
import sensor, image, time
sensor.reset()
sensor.set_pixformat(sensor.GRAYSCALE) # 灰度化
sensor.set_framesize(sensor.QVGA) # 设置分辨率为 320x240
sensor.skip_frames(time=2000)
while True:
img = sensor.snapshot()
img.binary([ (128, 255) ]) # 二值化
# 进行目标检测或分类
# ...
优点:
缺点:
label_name、value 等)。.tflite 或 .onnx 格式时,注意是否支持 OpenMV 的推理引擎。如果你的任务是识别盒子上的两个固定位置的数字,可以考虑以下流程:
示例代码(OpenMV):
import sensor, image, math, time
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.skip_frames(time=2000)
# 加载模板图像
template_0 = image.Image("0_template.jpg")
template_1 = image.Image("1_template.jpg")
# ... 加载其他数字模板
while True:
img = sensor.snapshot()
# 找到数字区域(假设已知位置)
roi = img[100:150, 100:150] # 假设数字在该区域内
# 进行模板匹配
match_0 = roi.find_template(template_0, 0.7, step=4, search=image.SEARCH_EX)
if match_0:
print("Found 0")
match_1 = roi.find_template(template_1, 0.7, step=4, search=image.SEARCH_EX)
if match_1:
print("Found 1")
| 问题 | 解决方案 | |------|----------| | 训练准确率高但实际识别失败 | 数据分布不一致、模型泛化能力差 | | 提高识别准确率 | 优化训练数据、调整模型结构、改进预处理 | | 使用模板匹配 | 更适合固定位置、固定大小的目标识别 | | EdgeImpulse 注意事项 | 数据一致性、交叉验证、模型格式选择 |
如果你愿意提供具体的训练数据、模型配置或代码片段,我可以进一步帮你分析问题并给出定制化的优化建议。
分享 创建了问题
7月16日
创建了问题
7月16日


