
编译生成darknet.exe时报错如下
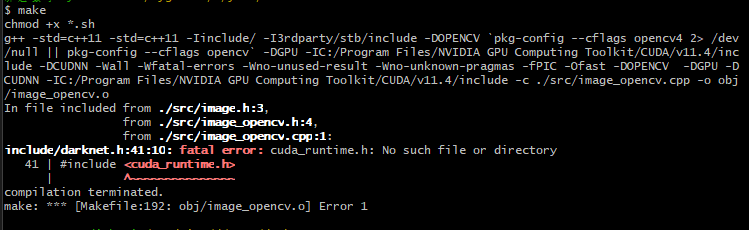
这是我的cuda路径
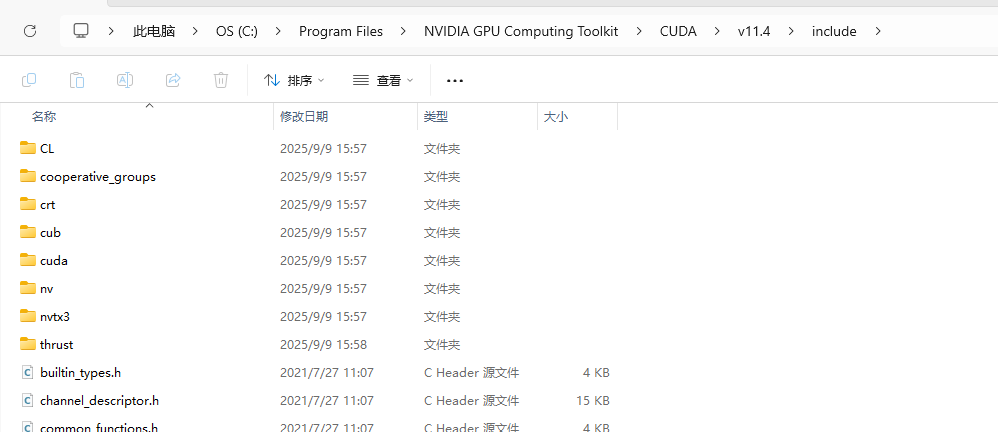
以下是我的makefile写法
GPU=1#以启用GPU支持图片处理器
CUDA=1#设置为1以启用GPU加速
CUDNN=1#cuDNN是用于深度神经网络的GPU加速库,启用它可以提高性能。
CUDNN_HALF=0
OPENCV=1
AVX=0
OPENMP=0
LIBSO=0
ZED_CAMERA=0
ZED_CAMERA_v2_8=0
# 设置 OpenCV 路径
#OPENCV_PATH=D:/OpenCV-MinGW-Build-OpenCV-4.5.2-x64
CUDA_PATH=C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.4
# set GPU=1 and CUDNN=1 to speedup on GPU
# set CUDNN_HALF=1 to further speedup 3 x times (Mixed-precision on Tensor Cores) GPU: Volta, Xavier, Turing and higher
# set AVX=1 and OPENMP=1 to speedup on CPU (if error occurs then set AVX=0)
# set ZED_CAMERA=1 to enable ZED SDK 3.0 and above
# set ZED_CAMERA_v2_8=1 to enable ZED SDK 2.X
USE_CPP=0
DEBUG=0
ARCH= -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52] \
-gencode arch=compute_61,code=[sm_61,compute_61]
OS := $(shell uname)
# Tesla A100 (GA100), DGX-A100, RTX 3080
# ARCH= -gencode arch=compute_80,code=[sm_80,compute_80]
# Tesla V100
# ARCH= -gencode arch=compute_70,code=[sm_70,compute_70]
# GeForce RTX 2080 Ti, RTX 2080, RTX 2070, Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000, Tesla T4, XNOR Tensor Cores
# ARCH= -gencode arch=compute_75,code=[sm_75,compute_75]
# Jetson XAVIER
# ARCH= -gencode arch=compute_72,code=[sm_72,compute_72]
# GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030, Titan Xp, Tesla P40, Tesla P4
# ARCH= -gencode arch=compute_61,code=sm_61 -gencode arch=compute_61,code=compute_61
# GP100/Tesla P100 - DGX-1
# ARCH= -gencode arch=compute_60,code=sm_60
# For Jetson TX1, Tegra X1, DRIVE CX, DRIVE PX - uncomment:
# ARCH= -gencode arch=compute_53,code=[sm_53,compute_53]
# For Jetson Tx2 or Drive-PX2 uncomment:
# ARCH= -gencode arch=compute_62,code=[sm_62,compute_62]
VPATH=./src/
EXEC=darknet
OBJDIR=./obj/
ifeq ($(LIBSO), 1)
LIBNAMESO=libdarknet.so
APPNAMESO=uselib
endif
ifeq ($(USE_CPP), 1)
#CC=g++
CC=x86_64-pc-cygwin-g++
else
#CC=gcc
CC=x86_64-pc-cygwin-gcc
endif
CPP=g++ -std=c++11
NVCC=nvcc
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -I3rdparty/stb/include
CFLAGS=-Wall -Wfatal-errors -Wno-unused-result -Wno-unknown-pragmas -fPIC
ifeq ($(DEBUG), 1)
#OPTS= -O0 -g
#OPTS= -Og -g
COMMON+= -DDEBUG
CFLAGS+= -DDEBUG
else
ifeq ($(AVX), 1)
CFLAGS+= -ffp-contract=fast -mavx -mavx2 -msse3 -msse4.1 -msse4.2 -msse4a
endif
endif
CFLAGS+=$(OPTS)
ifneq (,$(findstring MSYS_NT,$(OS)))
LDFLAGS+=-lws2_32
endif
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
#COMMON+= -I$(OPENCV_PATH)/include
#LDFLAGS+= -L$(OPENCV_PATH)/x64/mingw/lib
#LDFLAGS+= -lopencv_core -lopencv_highgui -lopencv_imgproc -lopencv_objdetect
LDFLAGS+=`pkg-config --libs opencv4 2> /dev/null || pkg-config --libs opencv`
COMMON+=`pkg-config --cflags opencv4 2> /dev/null || pkg-config --cflags opencv`
endif
ifeq ($(OPENMP), 1)
ifeq ($(OS),Darwin) #MAC
CFLAGS+= -Xpreprocessor -fopenmp
else
CFLAGS+= -fopenmp
endif
LDFLAGS+= -lgomp
endif
ifeq ($(GPU), 1)
#COMMON+= -DGPU -I/usr/local/cuda/include/
COMMON+= -DGPU -I$(CUDA_PATH)/include
CFLAGS+= -DGPU
ifeq ($(OS),Darwin) #MAC
#LDFLAGS+= -L/usr/local/cuda/lib -lcuda -lcudart -lcublas -lcurand
LDFLAGS+= -L$(CUDA_PATH)/lib -lcuda -lcudart -lcublas -lcurand
else
#LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
LDFLAGS+= -L$(CUDA_PATH)/lib/x64 -lcuda -lcudart -lcublas -lcurand
endif
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
ifeq ($(OS),Darwin) #MAC
#CFLAGS+= -DCUDNN -I/usr/local/cuda/include
CFLAGS+= -DCUDNN -I$(CUDA_PATH)/include
LDFLAGS+= -L/usr/local/cuda/lib -lcudnn
#LDFLAGS+= -L$(CUDA_PATH)/lib -lcudnn
else
#CFLAGS+= -DCUDNN -I/usr/local/cudnn/include
CFLAGS+= -DCUDNN -I$(CUDA_PATH)/include
#LDFLAGS+= -L/usr/local/cudnn/lib64 -lcudnn
LDFLAGS+= -L$(CUDA_PATH)/lib/x64 -lcudnn
endif
endif
ifeq ($(CUDNN_HALF), 1)
COMMON+= -DCUDNN_HALF
CFLAGS+= -DCUDNN_HALF
ARCH+= -gencode arch=compute_70,code=[sm_70,compute_70]
endif
ifeq ($(ZED_CAMERA), 1)
CFLAGS+= -DZED_STEREO -I/usr/local/zed/include
#CFLAGS+= -DZED_STEREO -I$(CUDA_PATH)/include
ifeq ($(ZED_CAMERA_v2_8), 1)
LDFLAGS+= -L/usr/local/zed/lib -lsl_core -lsl_input -lsl_zed
#-lstdc++ -D_GLIBCXX_USE_CXX11_ABI=0
else
LDFLAGS+= -L/usr/local/zed/lib -lsl_zed
#-lstdc++ -D_GLIBCXX_USE_CXX11_ABI=0
endif
endif
OBJ=image_opencv.o http_stream.o gemm.o utils.o dark_cuda.o convolutional_layer.o list.o image.o activations.o im2col.o col2im.o blas.o crop_layer.o dropout_layer.o maxpool_layer.o softmax_layer.o data.o matrix.o network.o connected_layer.o cost_layer.o parser.o option_list.o darknet.o detection_layer.o captcha.o route_layer.o writing.o box.o nightmare.o normalization_layer.o avgpool_layer.o coco.o dice.o yolo.o detector.o layer.o compare.o classifier.o local_layer.o swag.o shortcut_layer.o activation_layer.o rnn_layer.o gru_layer.o rnn.o rnn_vid.o crnn_layer.o demo.o tag.o cifar.o go.o batchnorm_layer.o art.o region_layer.o reorg_layer.o reorg_old_layer.o super.o voxel.o tree.o yolo_layer.o gaussian_yolo_layer.o upsample_layer.o lstm_layer.o conv_lstm_layer.o scale_channels_layer.o sam_layer.o
ifeq ($(GPU), 1)
LDFLAGS+= -lstdc++
OBJ+=convolutional_kernels.o activation_kernels.o im2col_kernels.o col2im_kernels.o blas_kernels.o crop_layer_kernels.o dropout_layer_kernels.o maxpool_layer_kernels.o network_kernels.o avgpool_layer_kernels.o
endif
OBJS = $(addprefix $(OBJDIR), $(OBJ))
DEPS = $(wildcard src/*.h) Makefile include/darknet.h
all: $(OBJDIR) backup results setchmod $(EXEC) $(LIBNAMESO) $(APPNAMESO)
ifeq ($(LIBSO), 1)
CFLAGS+= -fPIC
$(LIBNAMESO): $(OBJDIR) $(OBJS) include/yolo_v2_class.hpp src/yolo_v2_class.cpp
$(CPP) -shared -std=c++11 -fvisibility=hidden -DLIB_EXPORTS $(COMMON) $(CFLAGS) $(OBJS) src/yolo_v2_class.cpp -o $@ $(LDFLAGS)
$(APPNAMESO): $(LIBNAMESO) include/yolo_v2_class.hpp src/yolo_console_dll.cpp
$(CPP) -std=c++11 $(COMMON) $(CFLAGS) -o $@ src/yolo_console_dll.cpp $(LDFLAGS) -L ./ -l:$(LIBNAMESO)
endif
$(EXEC): $(OBJS)
$(CPP) -std=c++11 $(COMMON) $(CFLAGS) $^ -o $@ $(LDFLAGS)
$(OBJDIR)%.o: %.c $(DEPS)
$(CC) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cpp $(DEPS)
$(CPP) -std=c++11 $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cu $(DEPS)
$(NVCC) $(ARCH) $(COMMON) --compiler-options "$(CFLAGS)" -c $< -o $@
$(OBJDIR):
mkdir -p $(OBJDIR)
backup:
mkdir -p backup
results:
mkdir -p results
setchmod:
chmod +x *.sh
.PHONY: clean
clean:
rm -rf $(OBJS) $(EXEC) $(LIBNAMESO) $(APPNAMESO)





