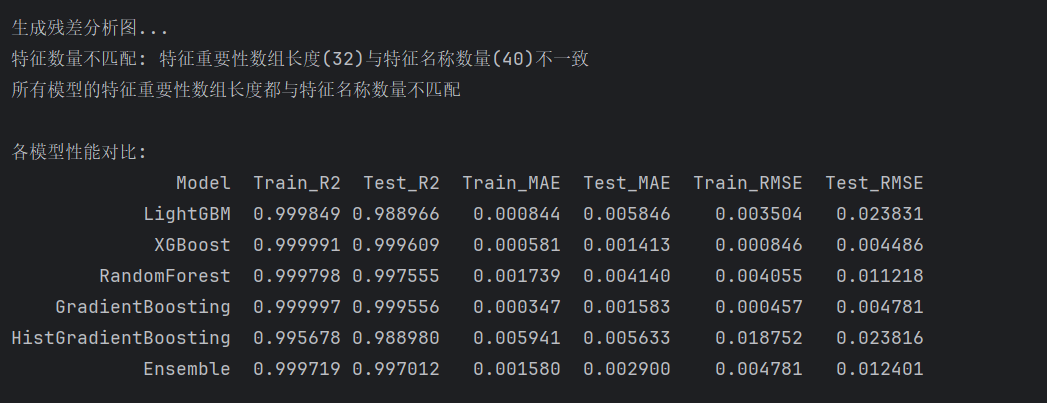
机器学习的性能怎么这么好,也没有数据泄露,但是总觉得有问题,麻烦看一下

 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
问题分析
根据你的描述,机器学习模型的性能非常好,没有数据泄露的迹象,但是你仍然感觉有问题。这个问题可能与以下几点相关:
解决方案
核心代码
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# 划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化模型
model = LogisticRegression()
# 调整超参数
param_grid = {'C': [0.1, 1, 10], 'penalty': ['l1', 'l2']}
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 评估模型
y_pred = grid_search.predict(X_test)
print('准确率:', accuracy_score(y_test, y_pred))
print('分类报告:')
print(classification_report(y_test, y_pred))
print('混淆矩阵:')
print(confusion_matrix(y_test, y_pred))
以上代码示例使用GridSearchCV来调整模型的超参数,评估模型的性能。
分享 创建了问题
10月16日
创建了问题
10月16日


