请教一下各位,我在训练Word2Vec模型的时候弹出了这些提示,请问是正常情况嘛?如果不是的话,请问要如何处理呢
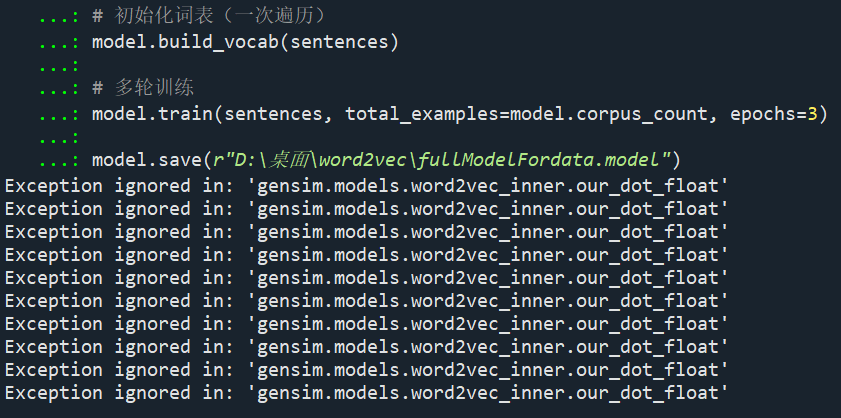
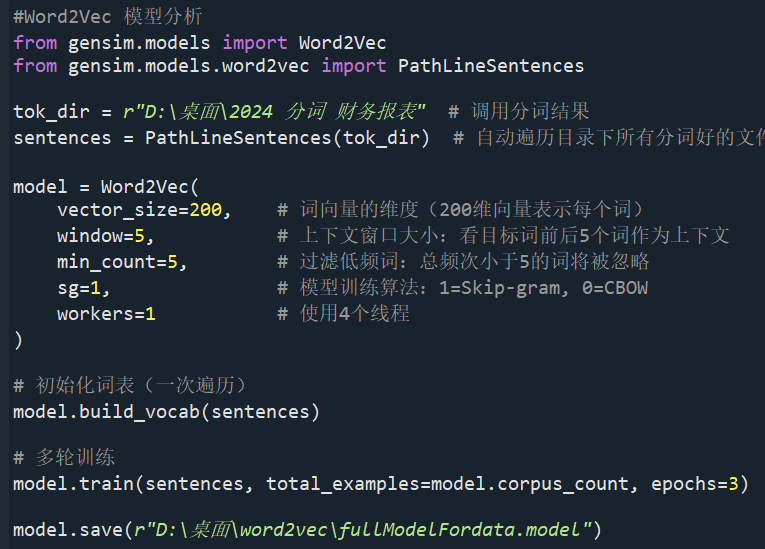

请教一下各位,我在训练Word2Vec模型的时候弹出了这些提示,请问是正常情况嘛?如果不是的话,请问要如何处理呢
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
Word2Vec中遇到的一些问题
根据你的描述,Word2Vec是用于自然语言处理的词向量学习算法,训练过程中可能会出现一些提示或警告。以下是可能的原因和解决方案:
如果训练数据量太小,Word2Vec可能会出现训练不稳定或收敛不良的问题。解决方案:
如果模型参数设置不合理,Word2Vec可能会出现训练不稳定或收敛不良的问题。解决方案:
如果训练数据质量不高,Word2Vec可能会出现训练不稳定或收敛不良的问题。解决方案:
如果计算资源不足,Word2Vec可能会出现训练不稳定或收敛不良的问题。解决方案:
如果以上解决方案无法解决问题,请检查Word2Vec的源码或文档,了解可能的原因和解决方案。
核心代码
from gensim.models import Word2Vec
# 加载训练数据
train_data = ...
# 创建Word2Vec模型
model = Word2Vec(train_data, size=100, window=5, min_count=1, workers=4)
# 训练模型
model.train(train_data, total_examples=len(train_data), epochs=10)
注意: 以上代码仅供参考,具体实现可能需要根据实际情况进行调整。
分享 修改了问题
11月8日
创建了问题
11月8日
修改了问题
11月8日
创建了问题
11月8日


