
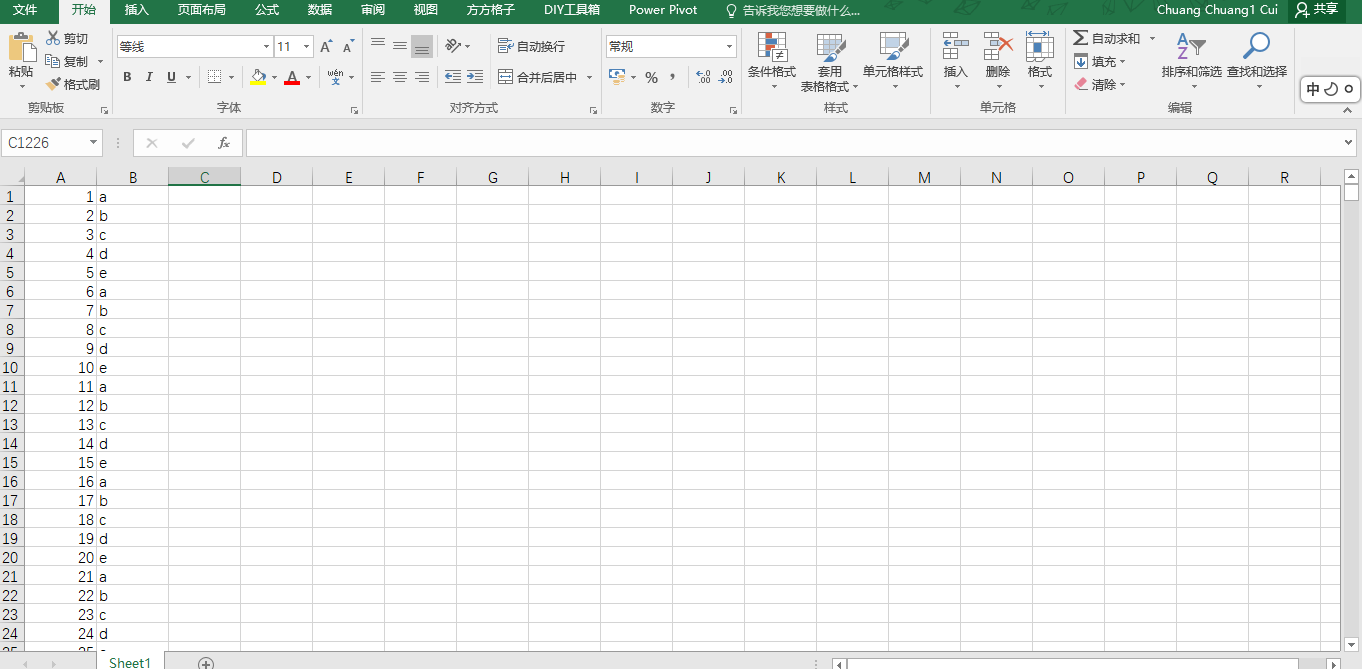
主要想实现分离excel数据,将数据按每500条分成一个sheet。但每次分离出来的数据虽然是500条,但第二个sheet第一个元素不是从第501开始,而是第50个开始的。详情看图
import os
import xlrd
import xlwt
from pip._vendor.distlib.compat import raw_input
# limit = raw_input('input limit number:')
limit = 500
readbook=r'D:\a\a.csv'
savebook=r'D:\b\bb.csv'
# readbook = raw_input('input excel read path:')
#
# savebook = raw_input('input excel save path:')
if limit == '':
limit = 50 # 默认按100条拆分
print ('拆分数量: ' + str(limit))
limit = int(limit)
# '/Users/huqiang/Desktop/shoplist.xls'
data = xlrd.open_workbook(readbook)
# 获取sheet
table = data.sheets()[0]
# 行数
nrows = table.nrows
print(nrows)
# 列数
ncols = table.ncols
if nrows % limit != 0:
sheets = (nrows // limit)+1
else:
sheets=nrows // limit
# sheets = (nrows // limit)+1
print(sheets)
# print str(nrows) + ' ' + str(ncols)
# print table10.cell(nrows - 1, ncols - 1).value
workbook = xlwt.Workbook(encoding='ascii')
for i in range(0, int(sheets)):
print('**',i)
worksheet = workbook.add_sheet(str(i))
for row in range(0, limit+1):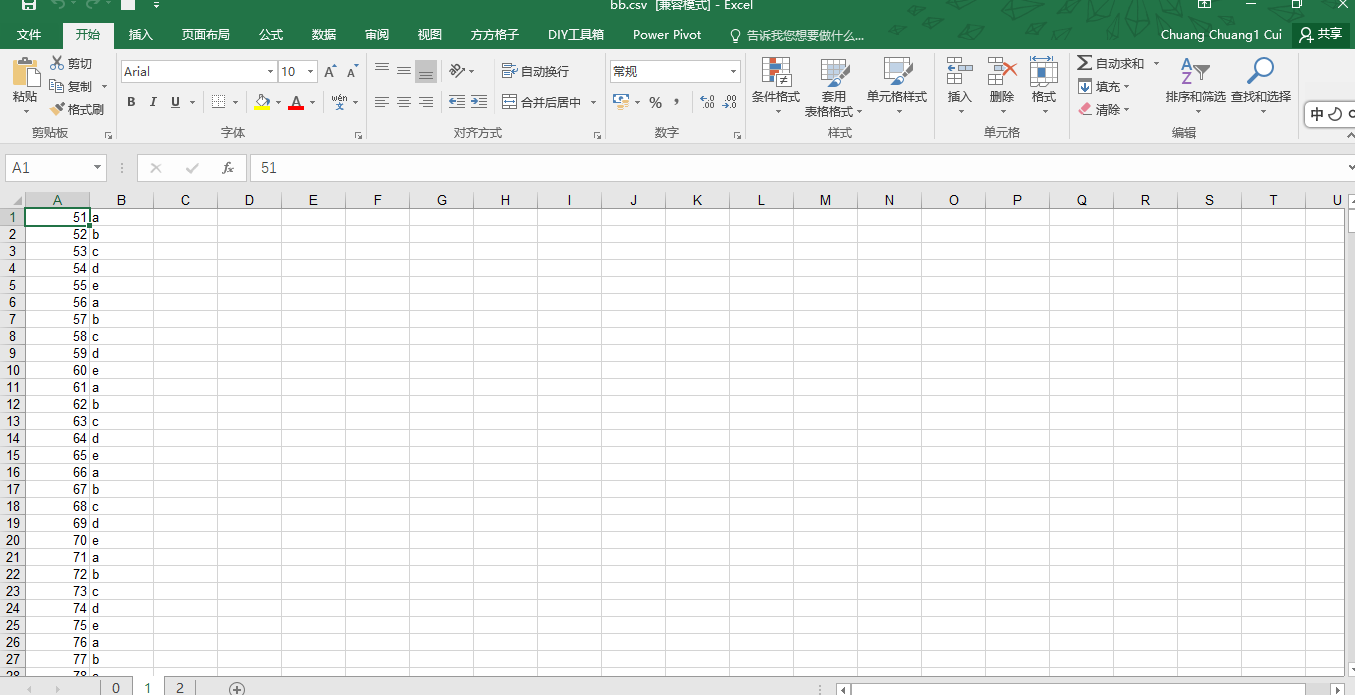
# print(row)
row_content = table.row_values(row + (i*50))
for col in range(0, ncols):
worksheet.write(row, col, row_content[col])
workbook.save(savebook)

g)




