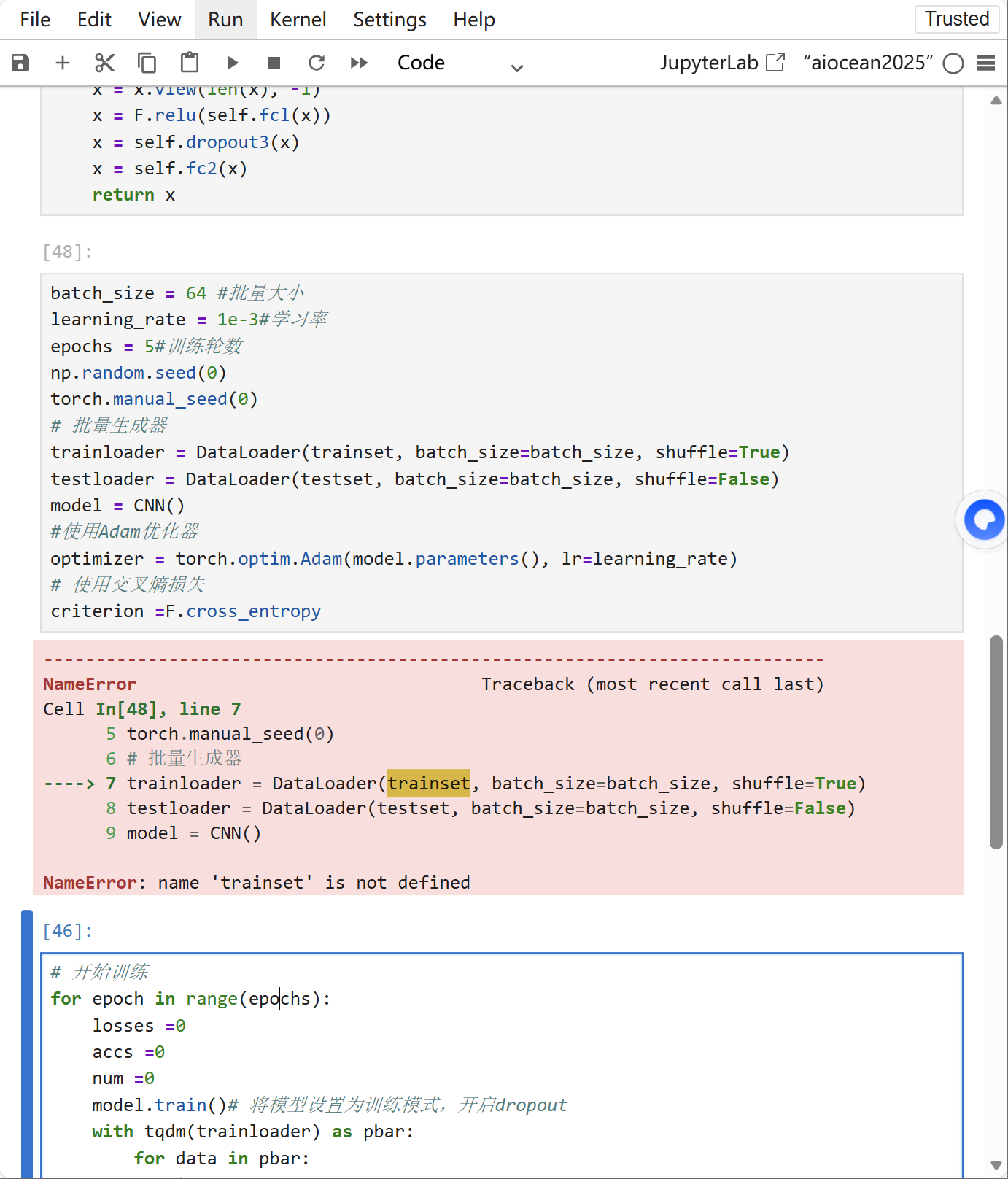
做这个动手实现卷积神经网络,照着已知的代码敲得,为啥在这个梯度下降训练的代码老报错,
说没有定义trainset,是什么意思啊,谢谢各位。

做这个动手实现卷积神经网络,照着已知的代码敲得,为啥在这个梯度下降训练的代码老报错,
说没有定义trainset,是什么意思啊,谢谢各位。
 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
trainset,这表明在代码中使用到了trainset这个变量,但在使用之前没有对其进行定义和赋值。trainset中,然后基于这个数据集进行模型训练,但实际代码中没有正确完成这一步骤。trainset应该是什么。通常它是一个包含训练数据和对应的标签的数据结构。torch库来构建卷积神经网络,常见的做法是使用torchvision库来加载数据集并进行预处理。假设要加载CIFAR10数据集:import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
torchvision.datasets.CIFAR10加载训练集数据,存储在trainset中。之后就可以使用trainset进行模型训练了,比如构建数据加载器:trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
torchvision库加载数据集的方式非常简洁和高效,它已经内置了很多常用数据集的加载函数,并且支持数据预处理。transform参数来实现,这有助于提高模型的泛化能力。torchvision库,如果项目对特定数据集有特殊的加载需求,可能无法直接满足,需要进行额外的开发。torchvision的数据集格式进行整理和转换,增加了一定的工作量。trainset是因为代码在使用该变量前未对其赋值。解决方法是根据具体需求正确定义和初始化trainset,常用的是利用相关库(如torchvision)来加载数据集。通过这种方式可以确保在梯度下降训练过程中有合适的训练数据可用,从而避免因未定义数据集而导致的错误。 希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 系统已结题
12月19日
系统已结题
12月19日 已采纳回答
12月11日
创建了问题
12月10日
已采纳回答
12月11日
创建了问题
12月10日


