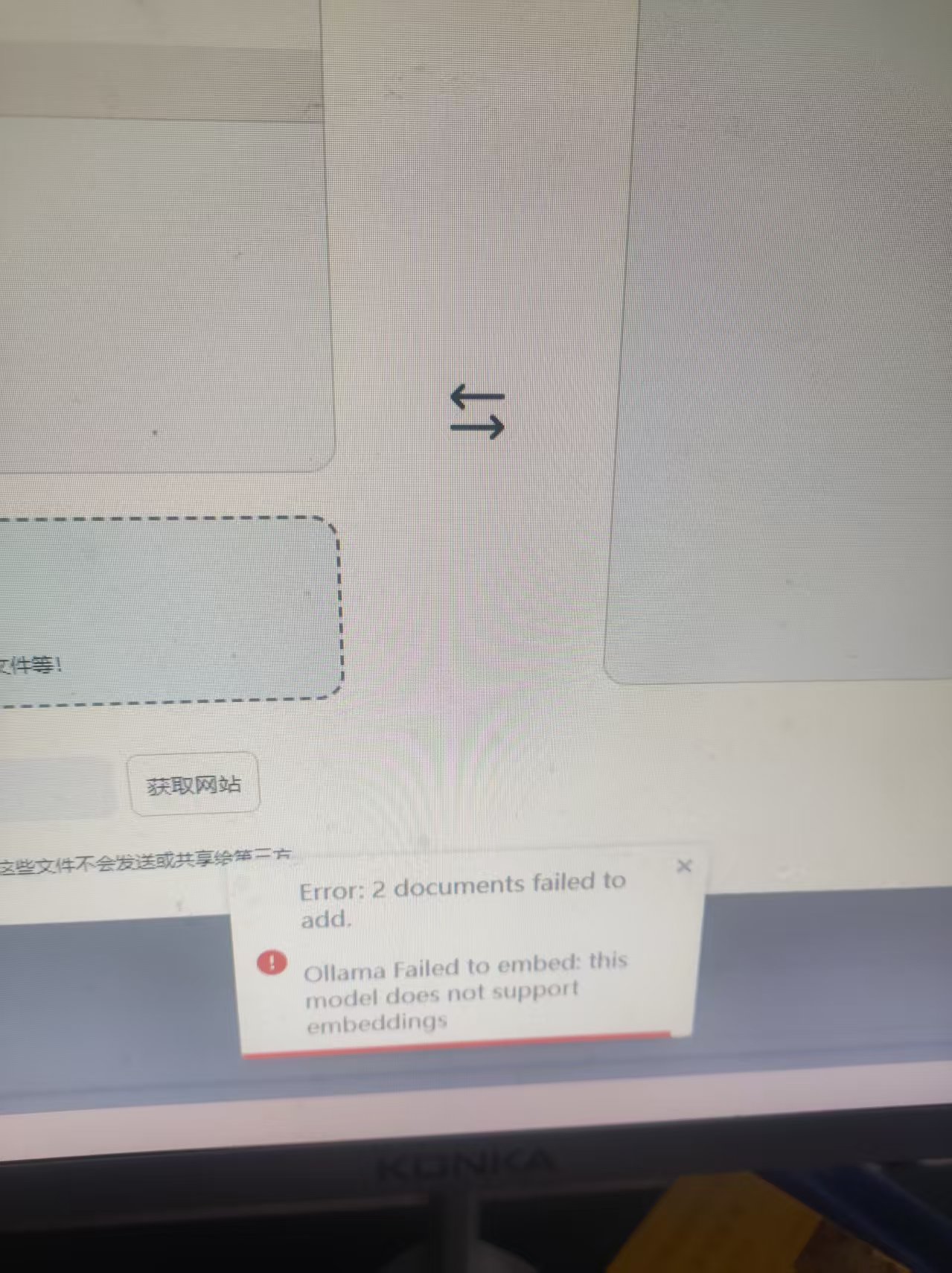
我想问一下我按照网上的设置已经设置好了ollama跟llm上面的,但是我上传pdf.跟txt文件却显示出错误,但是我上传有些表格文件却可以识别,这是为什么?
是我的文件问题还是我设置问题?

我想问一下我按照网上的设置已经设置好了ollama跟llm上面的,但是我上传pdf.跟txt文件却显示出错误,但是我上传有些表格文件却可以识别,这是为什么?
是我的文件问题还是我设置问题?
 分享
分享
中午好🌞🌞🌞
本答案参考通义千问
你提到的“anythinglln”可能是指 AnythingLLM,这是一个基于 Ollama 的本地大模型服务系统,支持多种文件格式(如 PDF、TXT、CSV 等)的上传与处理。你遇到的问题是:上传 PDF 和 TXT 文件时出错,但上传表格文件(如 CSV)却可以识别。这可能是由以下几个原因导致的,我将详细分析并给出解决方案。
llama3 或 codellama),某些模型对非结构化文本(如 PDF)的处理能力有限。phi3 或 nomic-embed-text 来提高对文本的处理能力。重点:确保文件是“可读”的文本格式。
config.yaml 或启动脚本中的模型名称,尝试以下模型:
model: phi3
# 或
model: nomic-embed-text
重点:选择更适合文本处理的模型。
重点:避免超过 Ollama 的默认文件大小限制。
重点:文件路径和权限设置错误会导致无法读取文件。
logs/ 目录下)。tail -f logs/anythingllm.log
Error: Failed to load file 'example.pdf'
那么可能是文件路径或格式问题。
重点:日志信息是排查问题的关键。
如果你使用的是 docker-compose.yml 启动 AnythingLLM,可以修改如下部分:
services:
anythingllm:
image: anythingllm/anythingllm
ports:
- "3000:3000"
environment:
- MODEL=phi3 # 修改为适合文本处理的模型
- EMBEDDING_MODEL=nomic-embed-text
volumes:
- ./data:/app/data
| 问题原因 | 解决方案 |
|----------|----------|
| 文件格式不兼容 | 检查 PDF 是否为可搜索文本,TXT 编码是否正确 |
| 模型配置不当 | 更换为 phi3 或 nomic-embed-text 等更适合文本的模型 |
| 文件过大 | 分割文件或压缩内容 |
| 路径或权限问题 | 检查文件路径和权限设置 |
| 错误信息缺失 | 查看日志文件以获取详细错误信息 |
如果你能提供具体的错误信息或日志内容,我可以进一步帮你定位问题。希望以上内容对你有所帮助!
分享 创建了问题
1月28日
创建了问题
1月28日

