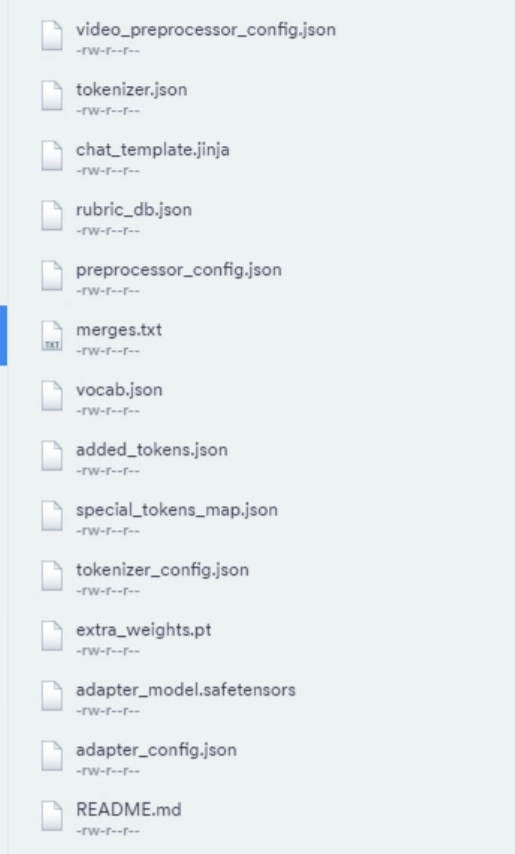
图片里是我做llm微调和自定义模块时候保存的权重文件,这个是最佳模型,同时还有一个全量的最佳模型,在做测试的时候加载这个增量权重的时候,结果低了10%以上(全量权重结果是正确的),但是同样一份代码,在其他显卡上运行,权重文件只有一个processor相关的,然后新显卡上这个最佳模型的增量权重和全量权重得到的测试结果就很正常,差不到1%,所以我不知道为什么这个图片里的权重加载结果就会低?测试代码都是同一个,加载方式也是,我这边觉得会不会是多出来的一些配置文件造成的?

 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
你描述的问题非常典型,涉及大模型微调后的权重加载问题,尤其是在不同硬件(如显卡)上表现不一致的情况。从你的描述来看,可能是以下几个关键原因导致的:
权重文件格式或结构不一致
processor相关参数等),那么在加载时可能会出现参数缺失或错误。显卡/硬件差异导致的精度问题
模型加载方式错误
strict=False 或者未正确设置设备(CPU/GPU),导致部分参数未被加载。processor),但加载时没有正确注册或初始化这些模块,也可能导致权重加载失败。权重文件损坏或不完整
数据预处理不一致
使用Python脚本加载权重文件,查看其内容是否完整:
import torch
# 加载权重文件
weights = torch.load("your_model.pth")
# 查看权重字典中的键
print(weights.keys())
检查是否有遗漏的关键参数(如model、processor等)。
确保加载的权重与当前模型结构完全匹配。你可以通过以下方式验证:
model = YourModelClass()
model.load_state_dict(torch.load("your_model.pth"), strict=False)
strict=False 来忽略不匹配的键,有助于发现是否有关键参数缺失。确认两个环境的CUDA版本、PyTorch版本、GPU型号是否一致。
确保在加载模型时,设备一致(如都使用cuda:0):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
检查是否启用了混合精度(如torch.cuda.amp),并确保在两个环境中使用相同的精度设置。
如果你在加载模型时没有正确设置设备或使用strict=False,可以参考以下修改:
# 修改前(可能出错)
model.load_state_dict(torch.load("best_model.pth"))
# 修改后(推荐)
model.load_state_dict(torch.load("best_model.pth"), strict=False)
如果你使用了自定义模块(如processor),请确保它们也被正确初始化:
# 初始化自定义模块
processor = CustomProcessor()
model.processor = processor
重点问题:
- 权重文件结构不一致
- 显卡/环境配置差异
- 模型结构与权重不匹配
- 数据预处理不一致
建议操作:
- 详细检查权重文件内容和结构
- 使用
strict=False加载权重- 确保模型结构与权重匹配
- 对比两个环境的软硬件配置
- 重新训练并测试一致性
如果你能提供具体的权重文件结构或代码片段,我可以进一步帮你定位具体问题。
分享 修改了问题
3月11日
创建了问题
3月11日
修改了问题
3月11日
创建了问题
3月11日


