
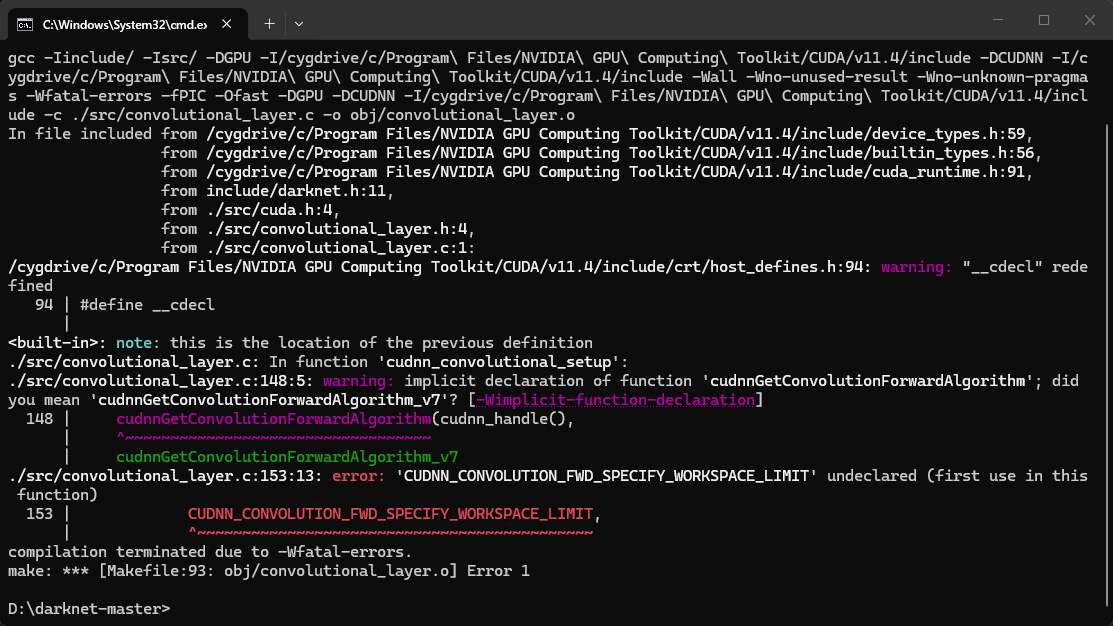
yolov3使用gpu编译生成darknet.exe报错./src/convolutional_layer.c:153:13: error: 'CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT' undeclared (first use in this function)
以下为makefile文件
GPU=1
CUDNN=1
OPENCV=0
OPENMP=0
DEBUG=0
CUDA_PATH=/cygdrive/c/Program\ Files/NVIDIA\ GPU\ Computing\ Toolkit/CUDA/v11.4#2026.4
ARCH= -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=[sm_50,compute_50] \
-gencode arch=compute_52,code=[sm_52,compute_52]
# -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
# This is what I use, uncomment if you know your arch and want to specify
# ARCH= -gencode arch=compute_52,code=compute_52
VPATH=./src/:./examples
SLIB=libdarknet.so
ALIB=libdarknet.a
EXEC=darknet
OBJDIR=./obj/
CC=gcc
CPP=g++
NVCC=nvcc
AR=ar
ARFLAGS=rcs
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -Isrc/
CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
ifeq ($(OPENMP), 1)
CFLAGS+= -fopenmp
endif
ifeq ($(DEBUG), 1)
OPTS=-O0 -g
endif
CFLAGS+=$(OPTS)
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv` -lstdc++
COMMON+= `pkg-config --cflags opencv`
endif
ifeq ($(GPU), 1)
#COMMON+= -DGPU -I/usr/local/cuda/include/#2026.4
COMMON+= -DGPU -I$(CUDA_PATH)/include
CFLAGS+= -DGPU
#LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand#2026.4
LDFLAGS+= -L$(CUDA_PATH)/lib -lcuda -lcudart -lcublas -lcurand
endif
ifeq ($(CUDNN), 1)
#COMMON+= -DCUDNN
COMMON+= -DCUDNN -I$(CUDA_PATH)/include
#CFLAGS+= -DCUDNN
CFLAGS+= -DCUDNN -I$(CUDA_PATH)/include
LDFLAGS+= -lcudnn
endif
OBJ=gemm.o utils.o cuda.o deconvolutional_layer.o convolutional_layer.o list.o image.o activations.o im2col.o col2im.o blas.o crop_layer.o dropout_layer.o maxpool_layer.o softmax_layer.o data.o matrix.o network.o connected_layer.o cost_layer.o parser.o option_list.o detection_layer.o route_layer.o upsample_layer.o box.o normalization_layer.o avgpool_layer.o layer.o local_layer.o shortcut_layer.o logistic_layer.o activation_layer.o rnn_layer.o gru_layer.o crnn_layer.o demo.o batchnorm_layer.o region_layer.o reorg_layer.o tree.o lstm_layer.o l2norm_layer.o yolo_layer.o iseg_layer.o image_opencv.o
EXECOBJA=captcha.o lsd.o super.o art.o tag.o cifar.o go.o rnn.o segmenter.o regressor.o classifier.o coco.o yolo.o detector.o nightmare.o instance-segmenter.o darknet.o
ifeq ($(GPU), 1)
LDFLAGS+= -lstdc++
OBJ+=convolutional_kernels.o deconvolutional_kernels.o activation_kernels.o im2col_kernels.o col2im_kernels.o blas_kernels.o crop_layer_kernels.o dropout_layer_kernels.o maxpool_layer_kernels.o avgpool_layer_kernels.o
endif
EXECOBJ = $(addprefix $(OBJDIR), $(EXECOBJA))
OBJS = $(addprefix $(OBJDIR), $(OBJ))
DEPS = $(wildcard src/*.h) Makefile include/darknet.h
all: obj backup results $(SLIB) $(ALIB) $(EXEC)
#all: obj results $(SLIB) $(ALIB) $(EXEC)
$(EXEC): $(EXECOBJ) $(ALIB)
$(CC) $(COMMON) $(CFLAGS) $^ -o $@ $(LDFLAGS) $(ALIB)
$(ALIB): $(OBJS)
$(AR) $(ARFLAGS) $@ $^
$(SLIB): $(OBJS)
$(CC) $(CFLAGS) -shared $^ -o $@ $(LDFLAGS)
$(OBJDIR)%.o: %.cpp $(DEPS)
$(CPP) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.c $(DEPS)
$(CC) $(COMMON) $(CFLAGS) -c $< -o $@
$(OBJDIR)%.o: %.cu $(DEPS)
$(NVCC) $(ARCH) $(COMMON) --compiler-options "$(CFLAGS)" -c $< -o $@
obj:
mkdir -p obj
backup:
mkdir -p backup
results:
mkdir -p results
.PHONY: clean
clean:
rm -rf $(OBJS) $(SLIB) $(ALIB) $(EXEC) $(EXECOBJ) $(OBJDIR)/*







