
练习机器学习中,采用决策树将鸢尾花的数据进行分类,并绘制决策边界,代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data[:,2:]
y = iris.target
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth = 2,criterion = 'entropy')
dt_clf.fit(x,y)
def plot_decision_boundary(model,axis):
x0,x1 = np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*200)),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*200))
)
x_new = np.c_[x0.ravel(),x1.ravel()]
y_predict = model.predict(x_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,cmap = custom_cmap)
plot_decision_boundary(dt_clf,axis= [0.5,7.5,0,3])
plt.scatter(x[y==0,0],x[y==0,1])
plt.scatter(x[y==1,0],x[y==1,1])
plt.scatter(x[y==2,0],x[y==2,1])
plt.show() # 这个结果有点不对 ,但我又不知道哪里搞错了
第一次运行出现了下图所示的分类结果:
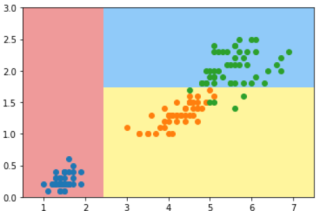
第二次及以后运行时出现了下图的分类结果:
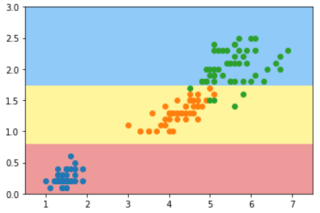
我想知道明明是相同的数据,相同的代码,只是运行先后顺序不同,为什么会出现上下两个图之间的完全不同的分类结果,并且出现哪种分类结果还有一定的随机性?我的代码里也没有随机数。虽然非参数学习对于数据依赖非常严重,但是我的数据也没有发生更改啊,很奇怪。








