
#问题描述:RuntimeError: CUDA out of memory.Tried to allocate 1.86GiB(GPU 3;23.70 GiB total capacity; 20.81 GiB already allocated; 1.10GiB free;20.92 GiB reserved in total by PyTorch)
#代码图片:
使用yolov7训练AI-TOD数据(大概27G左右),训练几个轮次之后会中断程序并报错。
使用yolov7-tiny结构是可以正常训练,使用yolov7标准版会报错
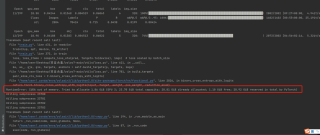
#我的初步解答思路:
1.改batch-size:缩小为8,4,2等,
2.改workers,改为4,2,1等
3.改img-size,将img-size改为【320,320】
以上三种方法可以让训练多几个epochs,但是最多十次左右还是会终止。
4.运行torch.cuda.empty_cache()函数。
放在代码之前没有作用,放在每个epoch后面直接报错
#操作环境及配置
ubuntu系统,3090显卡









