
我是为了写论文刚开始学Python,所以是带这问题学的,很多东西都不懂。我要实现的目的是将回答内容这列的文本中包含一些特定关键字的句子全部提取出来,并添加两列分别填入提取出来的句子对应的公司代码和年份。然后分析每一个单元格提取出来的句子的语调积极程度,并将语调积极程度的结果作为新的一列添加到表格中,最后输出为Excel,但是它报错了我不知道怎么解决,还烦请各位帮忙看一下怎么解决这个报错,然后就是我这个代码的逻辑是否有什么问题呢? 能否达到我想要的目的呢?希望大家能帮我解答一下疑惑,非常感谢!
数据示例:
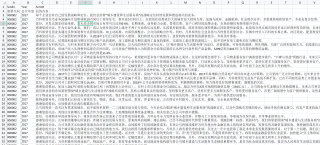
然后报错实在DataFrame那里
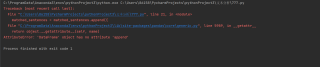
然后以下是我的代码
import pandas as pd
import re
from textblob import TextBlob
# 读取Excel文件
df = pd.read_excel('业绩说明会问答文本分析.xlsx')
# 定义需要匹配的关键字列表
keywords = ['推进', '发展', '提高']
# 遍历回答内容这一列,提取包含关键字的句子并添加到新的DataFrame中
matched_sentences = pd.DataFrame(columns=['Company Code', 'Year', 'Sentence'])
for i in range(len(df)):
text = str(df.iloc[i, 2]) # 获取回答内容这一列的文本
for keyword in keywords:
# 在文本中查找关键字,并提取包含关键字的句子
matches = re.findall(r'([^.]*' + keyword + '[^.]*\.)', text, re.IGNORECASE)
# 将句子和对应的公司代码和年份添加到新的DataFrame中
for match in matches:
matched_sentences = matched_sentences.append({
'Company Code': df.iloc[i, 0],
'Year': df.iloc[i, 1],
'Sentence': match
}, ignore_index=True)
# 遍历匹配的句子,提取语调积极程度并添加到新的一列中
positivity_scores = []
for sentence in matched_sentences['Sentence']:
blob = TextBlob(sentence)
positivity_scores.append(blob.sentiment.polarity)
matched_sentences['Positivity Score'] = positivity_scores
# 将最终结果输出为Excel文件
matched_sentences.to_excel('your_output_file_path.xlsx', index=False)








