
参照《从零开始学网络爬虫》案例,爬取豆瓣图书Top250的信息
https://book.douban.com/top250
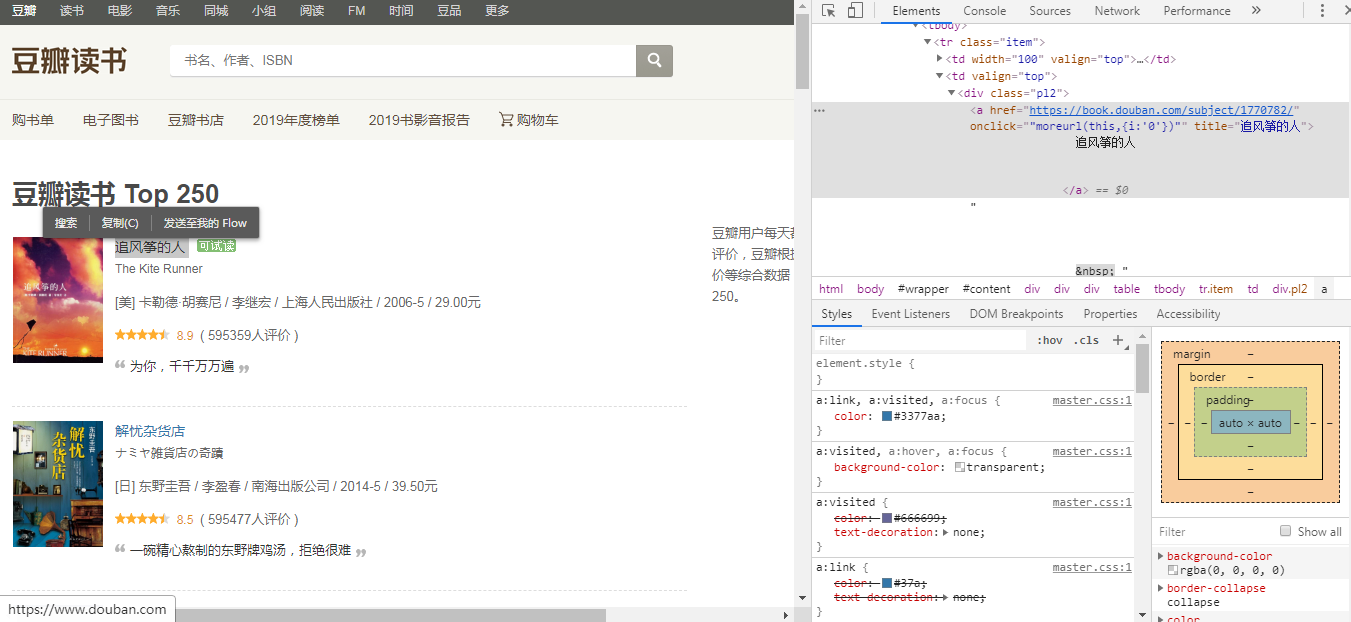
爬取前需要用XPath获取书名、作者等标签信息,在浏览器中检查网页信息,并右击,copy XPath获取元素的XPath
书中原版代码如下
import csv
from lxml import etree
import requests
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36'
}
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]
wenben = open('E:\demo.csv','wt',newline='',encoding='utf-8')
writer = csv.writer(wenben)
writer.writerow(('name','url','author','publisher','date','price','rate','comment'))
for url in urls:
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')[0]
url = info.xpath('td/div/a/@href')[0]
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher = book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')[0]
comments = info.xpath('td/div/span[2]/text()')[0]
comment = comments[0] if len(comments) != 0 else "空"
writer.writerow((name,url,author,publisher,date,price,rate,comment))
print(name)
wenben.close()
print("输出完成!")
可以发现,以书名为例,原版中获取的XPath如下
'td/div/a/@title'
但是我通过浏览器检查元素获取到的XPath如下
*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
而且按照自己获取的XPath进行爬取,并不能爬取到网页信息。只有按照原版的XPath才能正确爬取到网页信息。
请问各位大神,为什么从浏览器端获取的XPath与案例并不一致,如何自行获取正确的XPath





