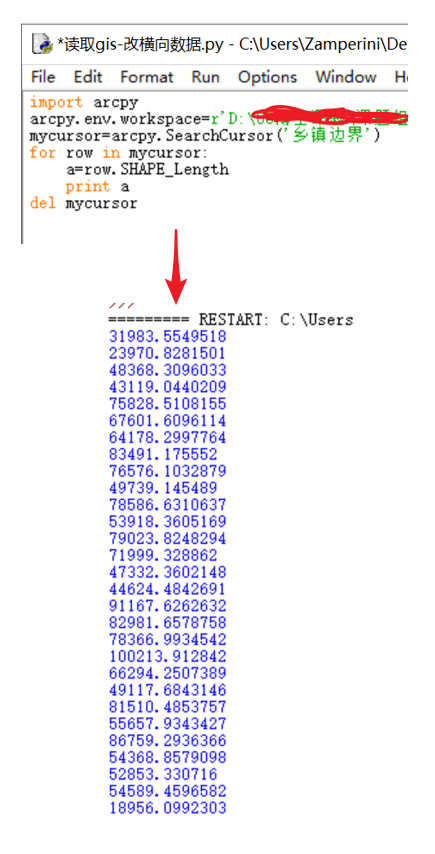
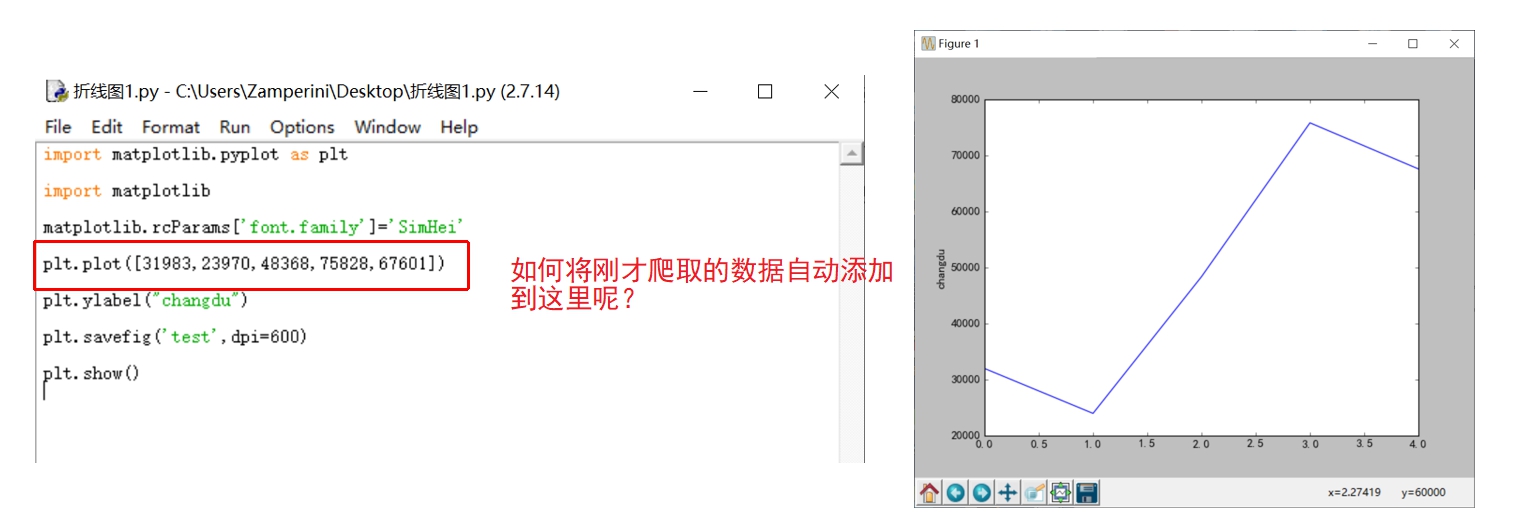
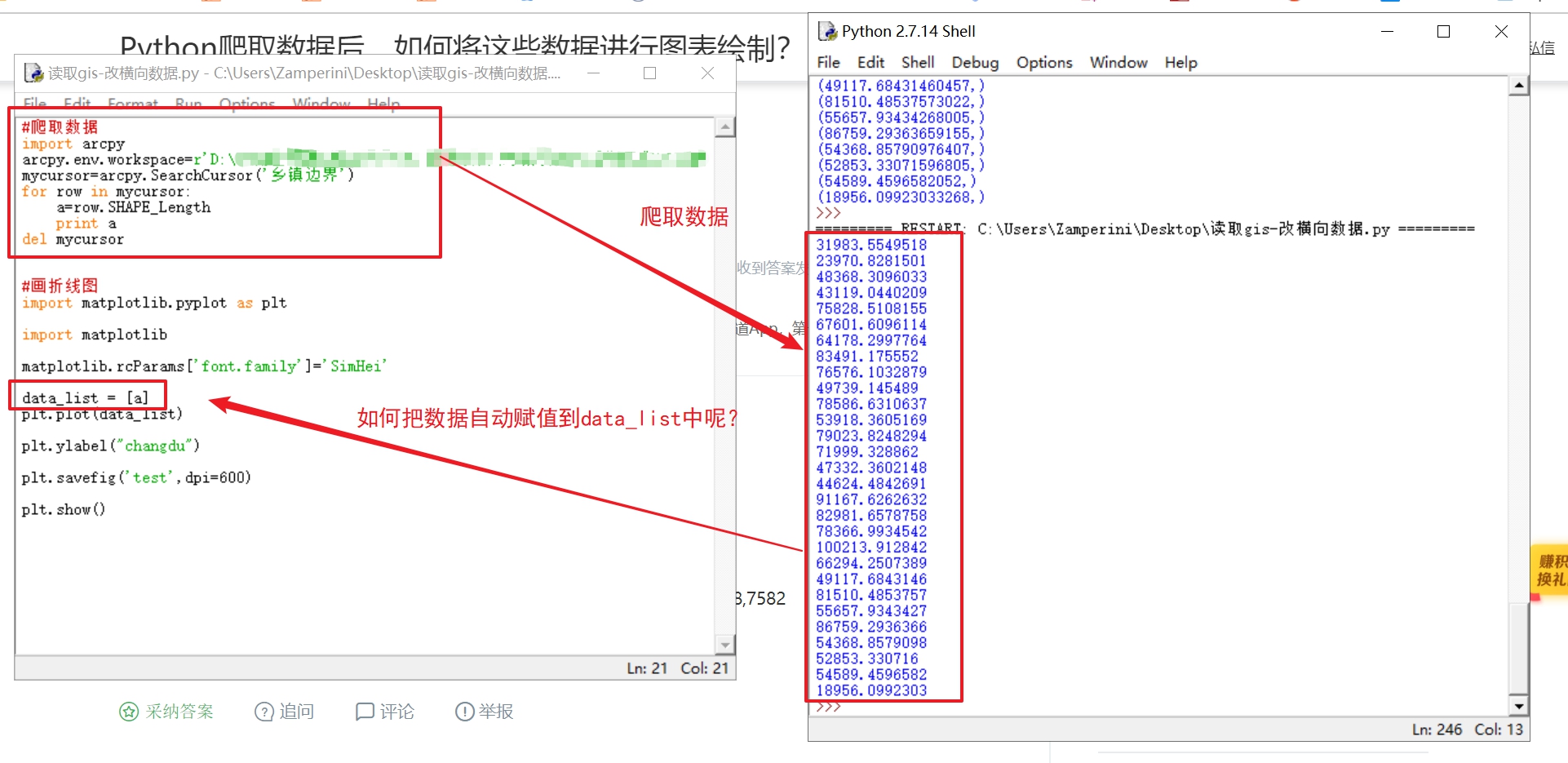
本人小白,在进行数据爬取后,如何将这些数据进行比如折线图的表达?折线图中的数据一般是手动输入的,但是对于爬取数据是一列一列的,如何把它进行格式更换呢?恳请各位大神解惑!!小弟跪谢!
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
定义个列表 DataList=[],然后用append函数就可以了
报告相同问题?

 分享 分享
分享 分享




