当我爬取某网站的评论的时候,有的评论由于过长,会隐藏一部分,这个时候需要我们点击”展开“才能看到完整的评论。
我是通过selenium模拟人工操作来获得动态渲染的网页内容,我尝试了通过xpath定位来模拟点击,但是一个页面可能有多个”展开“,那我到底应该怎么做,有没有什么办法可以获取所有”展开“,然后点击?页面如下: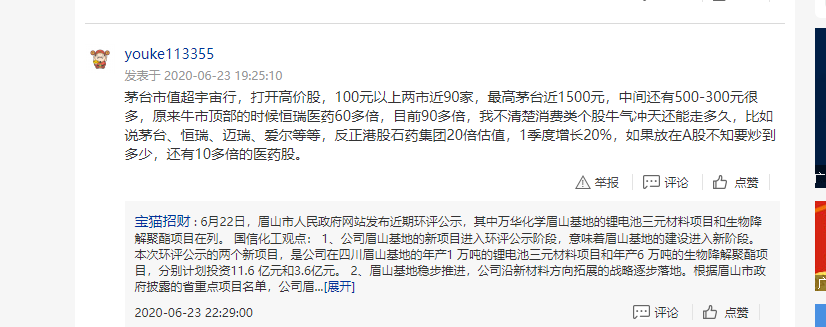
网址如下:
https://guba.eastmoney.com/news,600000,934143782.html

爬取网址中评论时,碰到多个”展开“应该怎么办?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答

- 2021-03-07 15:54回答 2 已采纳 两个方法一个 是找到后端接口,直接请求后端接口 另一个是操作selenium点击加载
- 2021-10-12 09:21回答 3 已采纳 题主这个内容是base64加密的,用base64.b64decode解密下就行了,需要导入base64模块,有帮助麻烦点个采纳【本回答右上角】,谢谢~~ import base64 lrc="W3R
- 2022-04-29 10:30回答 1 已采纳 需要在浏览器上临时显示后端实时处理的图像,需要将图像数据转成json字符串传输给js绘图。 后端python处理: import cv2 as cvfrom encodings import base
- 2019-06-07 21:26AI科技大本营的博客 故事的开始源于去年的技术雷达峰会,我在会上做了一场关于平台崛起的主题分享(《The Rise of Platform》),这场分享主要是从技术的层面从Global的视角介绍了平台化的兴起,以及分享从基础设施到人工智能等各个领域...
- 2022-02-13 21:26回答 2 已采纳 寻找200多个链接的规律呀,先爬取200多个链接放到列表里,然后便历链接列表对每个链接发请求就行
- 2021-05-12 18:21回答 6 已采纳 可以使用concurrent.futures的ThreadPoolExecutor,用一个线程池执行异步调用。例: import requests from bs4 import Beautifu
- 2022-01-27 15:14回答 3 已采纳 直接请求数据接口获取数据接口,不需要用selenium采集,代码如下 import requests import time headers = { 'user-Agent':'Mozilla/5.
- 2024-05-02 07:54m0_73979992的博客 大家好,本文将围绕python爬虫 70个python练手项目列表展开说明,80个python练手项目百度网盘是一个很多人都想弄明白的事情,想搞清楚python练手经典100例项目需要先了解以下几个事情。今天博主给大家带来了一份大礼...
- 2021-08-11 23:59回答 2 已采纳 你是真的秀,没有请求图片地址获得数据肯定打不开啊,你写入的是列表的的文本的二进制,并不是图片的。应该在图片链接后面再请求一次图片网址,然后写入获得的响应数据的二进制内容,望采纳哈
- 2022-08-25 16:21回答 5 已采纳 emmm,你可以先打开浏览器进行登录,再让selenium接管浏览器:https://blog.csdn.net/qq254271304/article/details/103493969或者你再程序
- 2021-10-24 12:56回答 1 已采纳 遇到VIP页面,我想你应该需要一个VIP会员,并以登入破解。 限制爬取次数上,可以用proxy轮转 或 尽量拉长sleep时间 或 多办几个账号 以上浅见
- 2022-02-21 00:25文默的博客 )这个问题看第二回里面的第二点吧~~ 整理文章:JavaScript基础知识-变量 四:知识点:深拷贝和浅拷贝(21/09/09) 因为什么而诞生的: 首先我们应该知道,除了引用型数据是存储在堆中的,其他类型都是存储在栈中的...
- 2021-03-18 16:10回答 5 已采纳 完整代码 import requests from bs4 import BeautifulSoup import time import pandas as pd import numpy as
- 2020-08-11 11:53u25th_engineer的博客 项 目 名 称: AI云学习 —— 一款基于Spark构建知识图谱的人工智能学习工具 项 目 类 型: “互联网+”信息技术服务业 项 目 负责人: 文华 高 校: 合肥工业大学(宣城校区) 院 系: ...
- 2020-05-17 22:51天秤座的架构师的博客 要做好整个企业的云原生体系建设,需要有个总体的视角,不谋全局者,不足以谋一域。我们将企业的架构进行全方面的梳理,并给出云原生体系建设总图,这个图当然不是一蹴而就就能建设完毕的,而是根据业务需求不断迭代...
- 没有解决我的问题, 去提问


悬赏问题
- ¥20 关于#硬件工程#的问题,请各位专家解答!
- ¥15 关于#matlab#的问题:期望的系统闭环传递函数为G(s)=wn^2/s^2+2¢wn+wn^2阻尼系数¢=0.707,使系统具有较小的超调量
- ¥15 FLUENT如何实现在堆积颗粒的上表面加载高斯热源
- ¥30 截图中的mathematics程序转换成matlab
- ¥15 动力学代码报错,维度不匹配
- ¥15 Power query添加列问题
- ¥50 Kubernetes&Fission&Eleasticsearch
- ¥15 報錯:Person is not mapped,如何解決?
- ¥15 c++头文件不能识别CDialog
- ¥15 Excel发现不可读取的内容