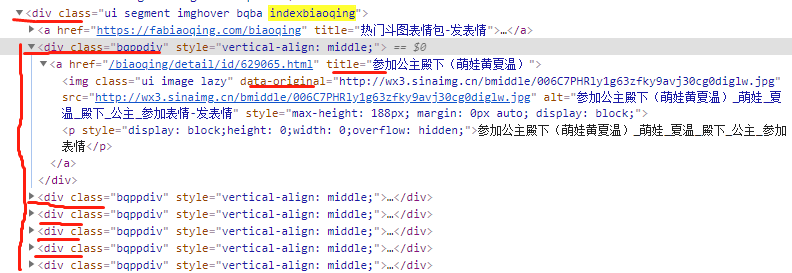
想要抓取所发表情里面的所有热门表情的名字和图片链接,但是只能抓取到第一个,如果删掉<div.+?indexbiaoqing.+? 则会返回其他模块表情包(能返回很多链接,但不是我想要的,仔细对照改了改还是不对),希望大佬指点
上代码
from urllib import request
import requests
import re
import time
import os
def main():
page_url = 'https://www.fabiaoqing.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'Cookie': 'PHPSESSID=595p4sic6t2omtl4fod2crj6kt; BAIDU_SSP_lcr=https://www.baidu.com/link?url=oDQDHox9F2MtoMApyh8BoSFQVz_d798fE1MSPPIeCiBbk0_0UksqN0_zvFvDfXoV&wd=&eqid=f372be560001f38e000000025f7315a9; __gads=ID=9b8c836a8fe9b3a1:T=1601385527:S=ALNI_Mavb6ihzHHKTZjw8P1TNcjakvzHrA; UM_distinctid=174da03f66d3fd-000604be2b9b57-333376b-100200-174da03f66e2e3; CNZZDATA1260546685=1101262114-1601380731-https%253A%252F%252Fwww.baidu.com%252F%7C1601380731'}
resp = requests.get(page_url, headers=headers)
text = resp.text
image_urls = re.findall(r' <div.+?indexbiaoqing.+?<div.+?bqppdiv.+?<a.+?data-original="(.+?)".+?>', text, re.VERBOSE | re.DOTALL)[0] # re.DOTALL表示小圆点也可以表示换行
print(image_urls)
names = re.findall(r'<div.+?indexbiaoqing.+?<div.+?bqppdiv.+?<a.+?title="(.+?)">', text, re.VERBOSE | re.DOTALL) # re.DOTALL表示小圆点也可以表示换行
print(names)
上关键出错代码
上结果
上页面代码