
我在做leetcode题的时候写的python程序中包含如下一段代码:
res = int(a, 2) + int(b, 2)
ans = []
while res > 0:
t = str(res % 2)
结果我先在python shell里面运行这个程序会报错:
然而我在python shell里面运行类似的代码,也把一个整型存放到res里,就没有问题:
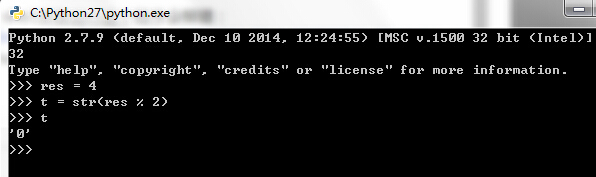
同样在eclipse中运行也是正常无误的:
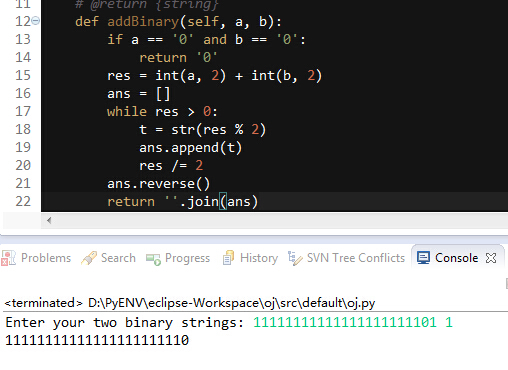
从图中也可以看到shell和命令行中的python都是2.7.9版本的,eclipse的python版本是2.7.3,但是我认为版本问题这不是导致报错与否的原因,请问有没有大神知道为啥命令行中执行会报TypeError呢?





