




1条回答 默认 最新

- 2021-09-11 14:26回答 2 已采纳
- 2017-12-12 08:19回答 9 已采纳 import urllib import urllib2 import re def craw(url, page): html1 = urllib2.Request(url)
- 2022-06-12 23:13回答 1 已采纳 except后面可以加 e,然后打印e。类似 except Exception as e: print("未知异常:%s" % e) 另外,你这样创建启动进程,似乎有点多。最
- 2023-08-04 10:08q56731523的博客 在进行Python爬虫任务时,遇到重定向问题是常见的问题之一。重定向是指在发送请求时,服务器会返回一个新的URL,将请求重新定向到该URL。为了帮助您解决这个问题,本文将提供一些实用的解决办法,并给出相关的代码...
- 2022-04-29 11:12回答 1 已采纳 我给你改了一下,你对比看看吧: from bs4 import BeautifulSoup import pandas as pd import requests def crawer_travel
- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
- 2023-02-14 11:17回答 4 已采纳 该回答引用ChatGPT根据错误信息,这个问题可能是由于连接超时或网络连接不可用导致的。因此,建议您检查以下几个方面: 确保您的网络连接正常并且能够访问请求的地址。确保请求的地址正确且存在,尝试在浏览
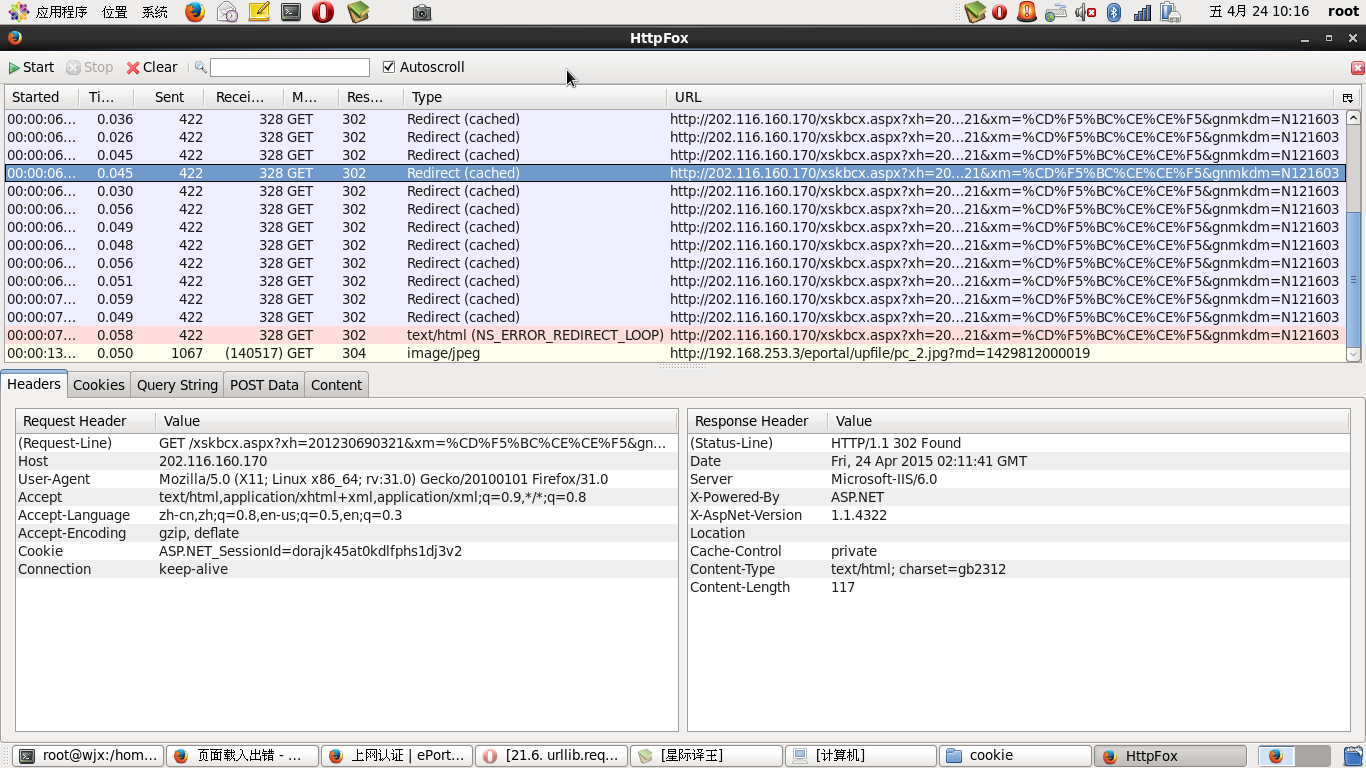
- 2021-10-02 12:26~Echo的博客 在用python模拟登陆时,如果登陆成功则会返回302状态码,接着就会请求登录成功后的主页...原来,如果没有禁止重定向,则requests返回的响应对象为进行重定向之后的响应对象 所以要判断是否为302的状态码,需要禁止
- 2021-12-30 23:54回答 2 已采纳 ulrs = re.findall('<img src="(.*?)" alt=".*?">', html) 改成这样就行了,有帮助的话采纳一下哦!谢谢!
- 2022-01-24 15:24回答 2 已采纳 jsonData='{"\u6d4b\u8bd5": 12345, "\u5185\u5bb9": ["\u6211\u4e5f\u4e0d\u77e5\u9053\u6211\u8981\u5199
- 2022-07-20 16:54回答 3 已采纳 首先,你这里写错了divs = query(".cm-content-box").items()
- 2020-12-15 21:15weixin_39662228的博客 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理以下文章来源于腾讯云,作者:周小董重定向问题在使用python爬虫的过程中难免会遇到很多301,...
- 2021-11-19 23:19回答 1 已采纳 re.findall(findChara, str(item)) 没有匹配到,返回的是空列表[] print(str(item)) 输出 没有<h3></h3>标签 你题目
- 2023-11-29 16:11小白学大数据的博客 重定向是指当用户请求一个URL...在Python爬虫开发中,处理重定向URL问题是非常的。我们使用可以请求库来处理重定向,通过查看重定向后的重要URL和重定向历史来了解重定向的情况,从而确保爬虫能够正确获取所需的数据。
- 2020-12-06 01:04weixin_40007175的博客 r = requests.get(url) print(r.text) 解决方案: s = requests.session() s.headers=headers r=s.get(url) 原因: 目前不清楚 python爬虫的重定向问题 重定向问题 在使用python爬虫的过程中难免会遇到很多301,302...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 HFSS 中的 H 场图与 MATLAB 中绘制的 B1 场 部分对应不上
- ¥15 如何在scanpy上做差异基因和通路富集?
- ¥20 关于#硬件工程#的问题,请各位专家解答!
- ¥15 关于#matlab#的问题:期望的系统闭环传递函数为G(s)=wn^2/s^2+2¢wn+wn^2阻尼系数¢=0.707,使系统具有较小的超调量
- ¥15 FLUENT如何实现在堆积颗粒的上表面加载高斯热源
- ¥30 截图中的mathematics程序转换成matlab
- ¥15 动力学代码报错,维度不匹配
- ¥15 Power query添加列问题
- ¥50 Kubernetes&Fission&Eleasticsearch
- ¥15 報錯:Person is not mapped,如何解決?