



1条回答 默认 最新
 threenewbee 2017-09-30 00:48关注
threenewbee 2017-09-30 00:48关注网页中有js脚本的话,可以在下载网页后动态修改/添加网页本身,也就是ajax
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2017-09-29 14:07回答 1 已采纳 网页中有js脚本的话,可以在下载网页后动态修改/添加网页本身,也就是ajax
- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
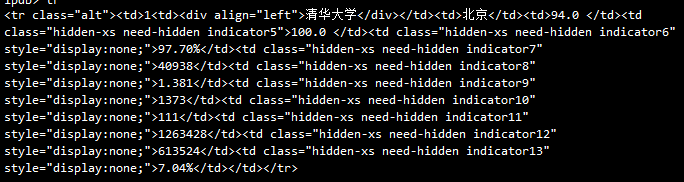
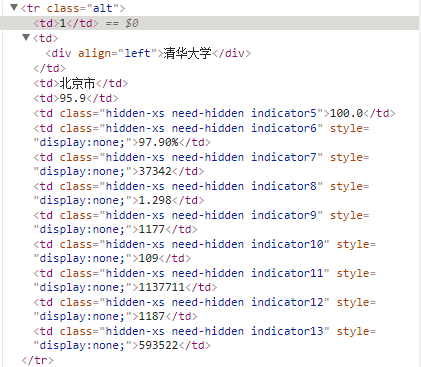
- 2022-03-08 22:50回答 2 已采纳 requests.get得到的是源代码,ajax动态加载或者js动态生成的html代码获取不到,需要直接请求接口获取数据或者从源代码中找到js数据源进行解析。截图中右边块的数据接口为下面这个,直接re
- 2020-09-18 22:53主要为大家详细介绍了Python爬虫学习之获取指定网页源码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
- 2021-11-19 14:39回答 1 已采纳 第一个问题,你用html.xpath('//div[@class="co_content8"]/ul/table')找不到,是因为在table那一类,有很多分支标签,所以定位不到具体的元素。第二个问题
- 2019-04-26 16:05回答 1 已采纳 现在都是动态网页,你爬取到的只是一个基本框架而已。 你可以用f12 然后检测一下http请求,基本上获取到的都是第一个请求。 后面的数据都是通过js修改后的网页。 交互式的。所以要想做复杂爬虫,
- 2021-10-31 23:19回答 1 已采纳 beautifulsoup是爬静态网页的,应该是有些内容属于动态,可以尝试selenium
- 2023-02-25 12:42python爬虫程序可用于收集数据。这也是最直接和最常用的方法。由于爬虫程序是一个程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用爬虫程序获取大量数据变得非常简单和快速。 由于99%以上的网站是...
- 2022-07-20 16:54回答 3 已采纳 首先,你这里写错了divs = query(".cm-content-box").items()
- 2021-11-27 19:16回答 2 已采纳 该页面数据是动态加载的,需要用此链接用post请求去获取https://www.xuetangx.com/api/v1/lms/get_product_list/?page=1
- 2022-02-24 11:15回答 2 已采纳 那个网站啊.你看下是不是写在接口中.F12开发者模式.选择XHR看下
- 2018-12-13 14:2381个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
- 2023-07-21 14:08在如此海量的信息碎片中,我们如何获取对自己有用的信息呢?答案是筛选!通过某项技术将相关的内容收集起来,在分析删选才能得到...利用python快速爬取网页有用信息,方便快捷,能够实现高效办公,高效分析,好用有效。
- 2022-01-11 19:52滚雪球~的博客 通过如下代码,会发现获取的网页源代码出现乱码 url = 'https://www.baidu.com' res = requests.get(url).text print(res) 出现乱码 查看python获得的编码格式 import requests # 0.通过如下代码,会发现获取的...
- 2020-12-22 19:08奇怪的同一个网站同一个榜单,只是页数不同,前若干页能爬取,后若干页就爬取不了,一度怀疑是不允许爬。 最后终于发现原因! 因为Cookie找错了(kao!!!!!) 注意要用这里的cookie! (下图是Chrome的开发者...
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 基于FOC驱动器,如何实现卡丁车下坡无阻力的遛坡的效果
- ¥15 IAR程序莫名变量多重定义
- ¥15 (标签-UDP|关键词-client)
- ¥15 关于库卡officelite无法与虚拟机通讯的问题
- ¥100 已有python代码,要求做成可执行程序,程序设计内容不多
- ¥15 目标检测项目无法读取视频
- ¥15 GEO datasets中基因芯片数据仅仅提供了normalized signal如何进行差异分析
- ¥100 求采集电商背景音乐的方法
- ¥15 数学建模竞赛求指导帮助
- ¥15 STM32控制MAX7219问题求解答